はじめに
文章自動生成をめざす、二回目です。前回は文章の構造を調べる形態素解析というのをやりました。今回は、.txtを読み込んで一文ずつに分けるということをしていきます。
文章を読み込む
事前にメモ帳などで作成したテキストデータを用意しておきます。エンコーディング方法には注意しておきましょう。(例では'utf-8'です。)では、文章を読み込んで表示しましょう。
import re
a = open('test.txt', 'r', encoding = "utf-8")
original_text = a.read()
print(original_text) #文章を表示
こんな感じになります。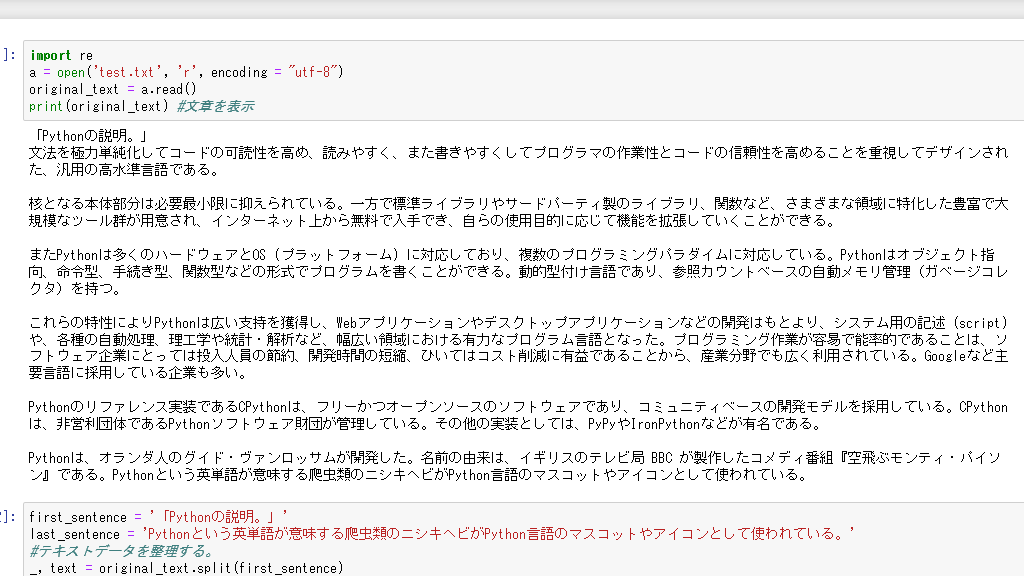
テキストデータを整理する
次にテキストデータを整理します。もととなるテキストの書き方次第で、各自調整が必要となります。コードは私のテキストデータの場合です。(例えば'文章(ぶんしょう)'などフリガナの場合は削除しなければならない。)
first_sentence = '「Pythonの説明。」'
last_sentence = 'Pythonという英単語が意味する爬虫類のニシキヘビがPython言語のマスコットやアイコンとして使われている。'
#テキストデータを整理する。
_, text = original_text.split(first_sentence)
text, _ = text.split(last_sentence)
text = first_sentence + text + last_sentence
text = text.replace('!', '。') #!や?を。に変える。全角半角に気を付ける
text = text.replace('?', '。')
text = text.replace('(', '').replace(')', '') #()を削除する。
text = text.replace('\r', '').replace('\n', '') # テキストデータの改行で表示される\nを削除
text = re.sub('[、「」?]', '', text)
sentences = text.split('。') #。で文章を一文単位に分割
print('文字数:', len(sentences))
sentences[:10] #10文を表示します
できたのがこれ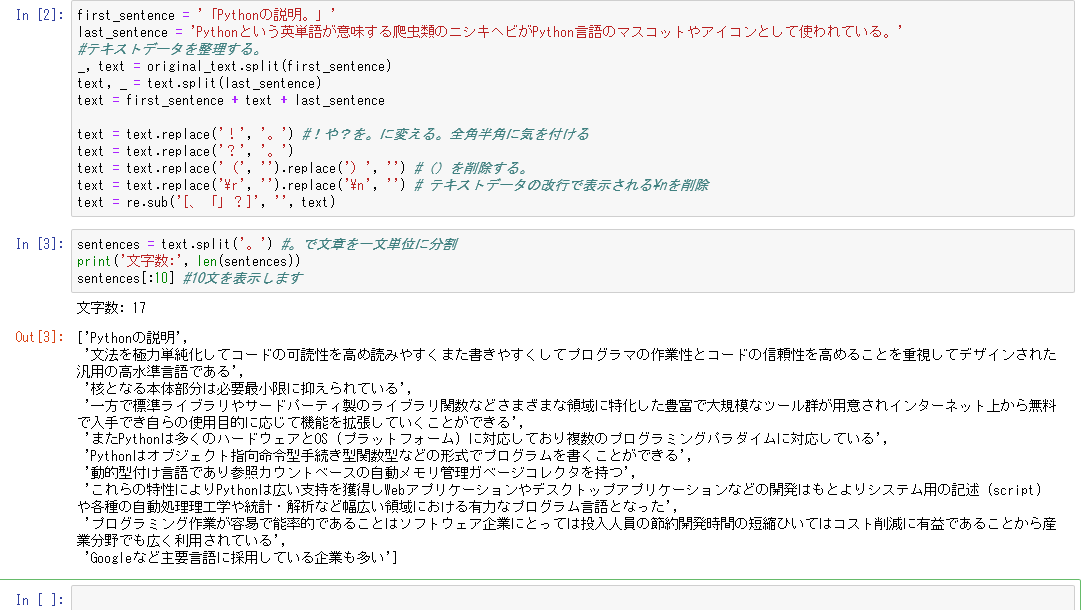
今回のコードはこれで以上です。これで一文単位のリストができましたね!これを形態素解析にかけて文章にしていく予定です。
雑談
個人的につまづいたところがいくつかあったので紹介。
- encoding = 'utf-8'を入れてなくてエラー。
- テキストデータの特徴がつかめてなくて'!'で一文が区切れない
といったところですかね。割と簡単なのに気づかなかったりして時間がかかりました。あと記事にする例文もどうしようか考えた末、無難なもの(WikipediaのPythonの説明文)となりました。