Dataiku DSS ver7から実装されたStatistics機能を使ってみたいと思います。基本統計量や、確率分布のフィッティングなどを簡単に確認することができる便利な機能です。
こちらの公式サイトを参考にしています。
プロジェクト~ワークシートの作成
Dataiku DSS上にStatistics学習用のプロジェクトが用意されていますので、早速使ってみましょう。
[+ NEW PROJECT]⇒[DSS tutorials]⇒[102: From Lab to Flow]
真ん中のorders_preparedデータセットをクリック。
Statisticsタブをクリック後、+ CREATE YOUR FIRST WORKSHEETをクリック。
以下のようなカードタイプ選択画面が表示されます。
現在は、この6種類の統計分析を行うことができます。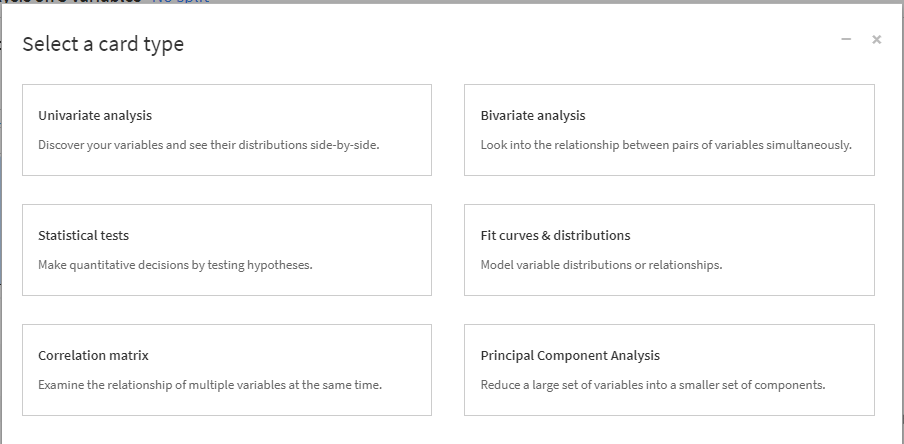
- Univariate analysis 基本統計量算出
- Statistical tests 統計検定実施
- Correlation matrix 相関係数計算
- Bivarate analysis 二変量解析
- Fit curves & distributions 確率分布へのフィッティング
- Principal Component Analysis 主成分分析
以降では、Univariate analysisとFit curves & distributionsについて紹介していきます。
ちなみに今回は取り上げませんが、二変量解析も便利そうです。二変数間での箱ひげ図やヒストグラム、散布図などを描くことができますので2変数間の関係数を把握することができます。
Univariate analysis
まずは、Univariate analysisを用いて、基本統計量を算出するカードを作成します。
基本統計情報を算出したい項目を選び、右上の+ボタンをクリックします。
今回は、pages_visitedとtshirt_categoryとtotalの3項目を選び、CREATE CARDをクリックします。
3項目選択し終えたら、CREATE CARDボタンをクリックします。
以下のように選択した3項目に対して基本統計量が算出されます。これれは「カード」と呼ばれます。1枚のカードに対して、1項目が対応する形となります。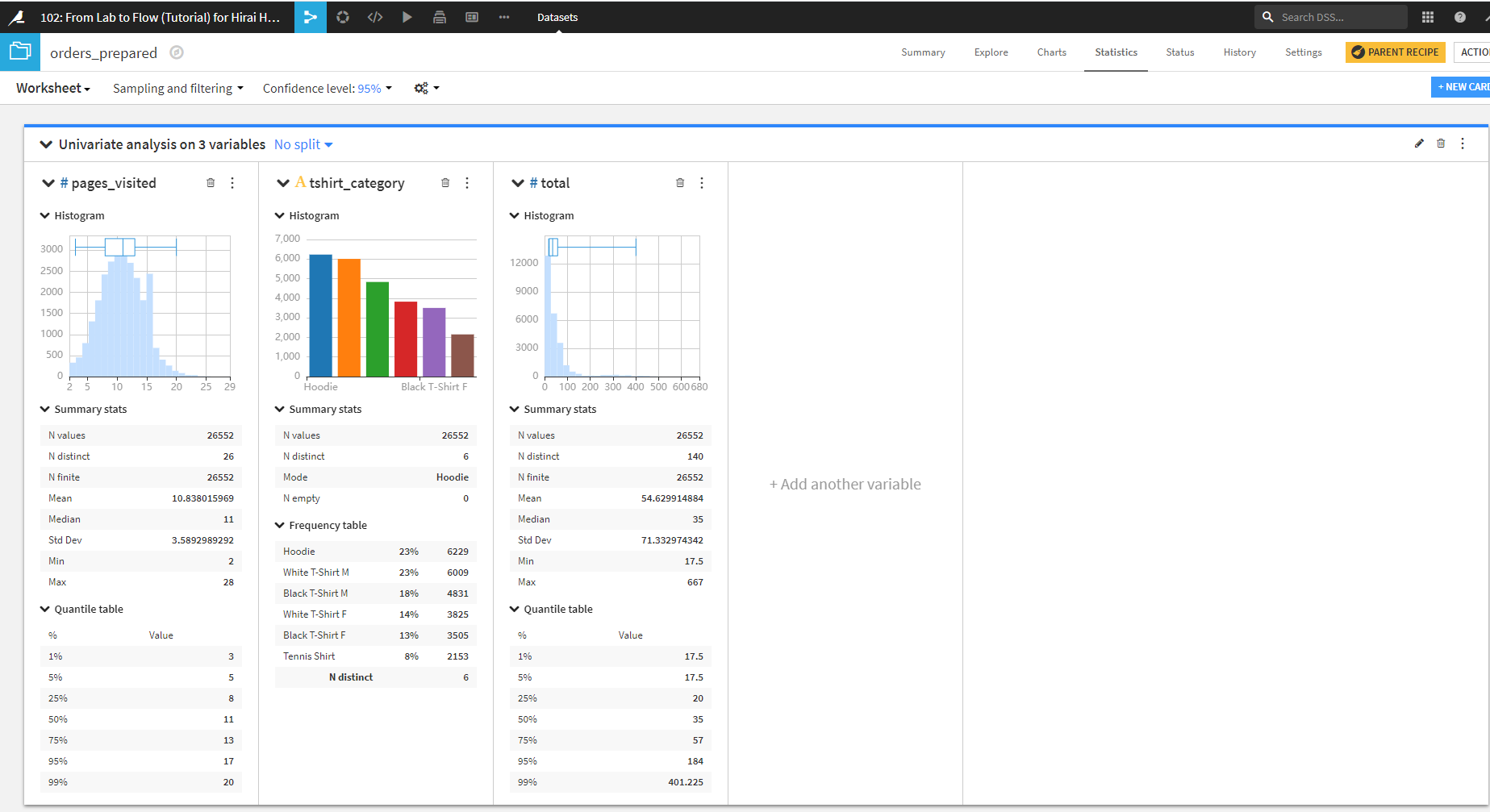
ポイントとしては、pages_visitedやtotalのような量的変数と、tshirt_categoryのような質的変数では出力内容が異なっています。
量的変数では、ヒストグラムや箱ひげ図で可視化され、最小値・最大値といった基本統計量や、パーセンタイルが示されます。ここでパーセンタイルとは、数値を昇順に並べた時に、全体のデータ数の中で25%点にある値、75%点にある値といったような統計値です。0%点が最小値、50%点が中央値、100%点が最大値となります。
質的変数では、要素数の多いものから順にヒストグラムで可視化され、基本統計量では最小値や最大値は意味がないため表示されず、欠損値や最頻値といったものが表示されています。また、パーセンタイルの代わりに、要素数の多いものから順に頻度テーブルが出力されています。
各カードに表示されているグラフの見栄えを編集することができます。
マウスオーバーにより、編集ボタンがでてきますのでクリック。
ヒストグラムのbin幅を変更可能です。
pages_visitedのbinsを100に変更してみると、左図のヒストグラムの見栄えが変わりました。
すべてのカードには、カード設定の編集、カードの複製または削除などのメニューが用意されています。
データのサンプリング
デフォルトでは、最初の10万行のみに対して計算していることに注意してください。データ全体に対して計算したければ、サンプリング設定を変更する必要があります。
Sampling methodの右側の▼をクリックすると、サンプリング設定を選択することができます。No samplingを選択肢、SAVE AND REFRESH SAMPLEをクリックすることでサンプル設定を変更できます。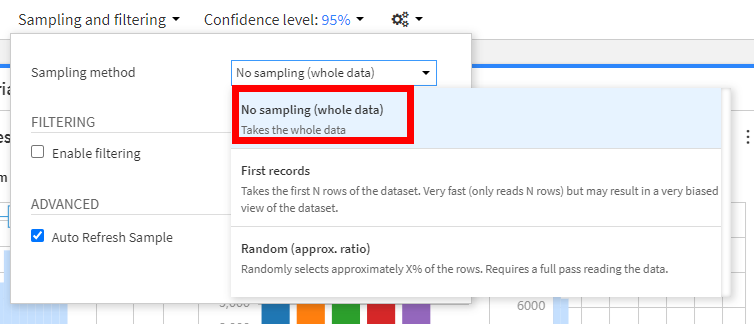
Fit Curves & distributions
Fit Curves & distributionsを使うと、選択した項目に対して、特定の確率分布のパラメータを推定することができます。推定結果から、選択した項目が特定の分布に従うかの検定結果や統計指標を可視化するカードを作成することができます。ここでは、total変数が指数分布に従うかどうかを確認してみます。
まずは+NEW CARDボタンをクリックします。
Fit Curves & distributionsを選択します。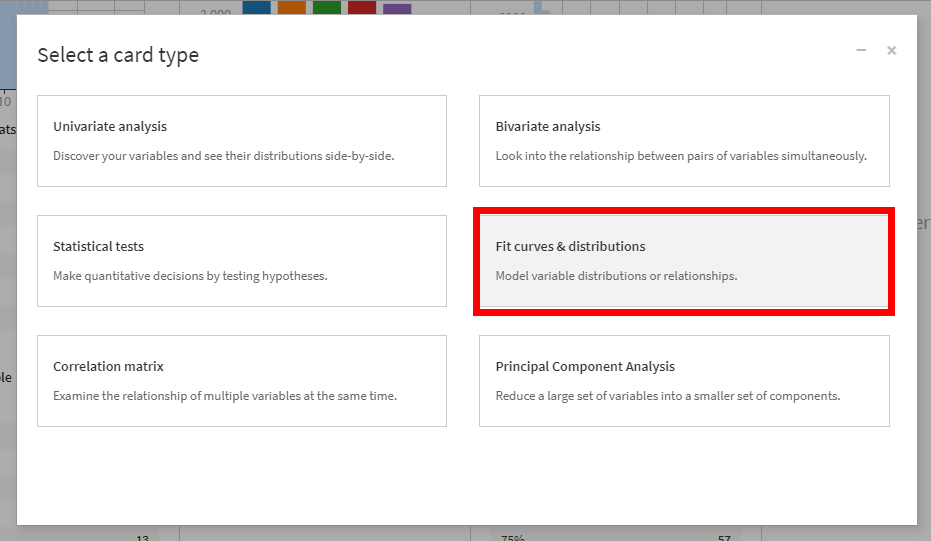
Fit distributionsを選択します。
Variableに選択したい項目を選択します。ここではtotalを選びましょう。
Distributionでは指数分布であるExponentialを選択してください。
最後にCREATE CARDをクリックします。
以下のように計算結果が得られます。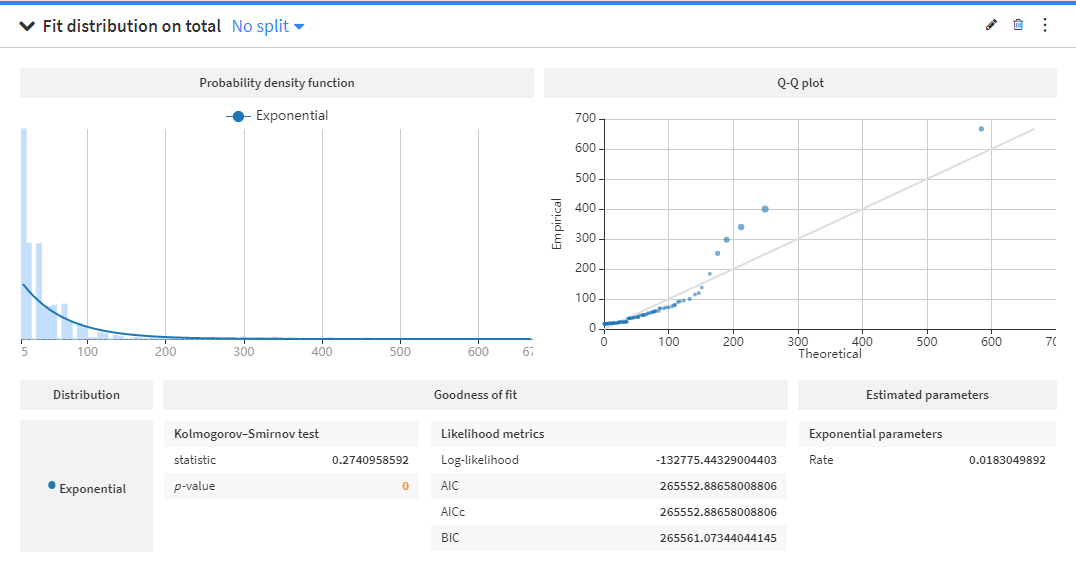
真ん中下のGoodness fitは、指数関数にフィットしたか検定結果や評価指標値が記載されています。
Kolomogorov-Siminov testでは、total項目の値の母集団の確率分布が、帰無仮説として提示された指数分布一致しているかどうかを検定したものです。p-valueが0となっているため、帰無仮説は棄却され、total項目は指数分布とはいえない、とみなせます。
Likelihood metricsは、今回推定したパラメータから得られる指数分布とtotal項目のデータの分布がどれくらい一致しているか、を示すものです。Log-likelihoodは高い方がよく、AIC、AICc、BICは小さいほうが良い値です。
これらの値は、相対的な指標となります。指数分布を当てはめた結果単品では判断できず、他の分布を当てはめた時の結果と比較して論じる値です。
右側にしめされているQ-Q分布は、2つの確率分布を互いに対してプロットしたグラフです。分布が一致する場合、中央の右肩上がりの直線に沿うようなグラフになりますが、一致しない場合は直線から乖離します。今回のデータは、途中から直線に沿っていないため、一部のデータが指数分布からはずれていると考えることができます。
ワークシートの編集など
2種類カードを作成してみましたが、それぞれのカードは結構大きいです。ワークシートは複数作成可能ですので、目的に合わせて複数のワークシートを使いわけるといった使い方が可能です。
New Worksheetをクリックすると、あたらしくワークシートが作成されて、既存のワークシートと切り替えて使うことができます。ワークシートの名前も変更可能です。
Intaractive Visual Statisticsには他にもいろいろな機能があります。詳細についてはこちらを参照してください。
おわりに
今まで地道にコツコツチャートで書いたり、Rで実装したりしていためんどくさい部分が、GUIで実装された印象です。
実務上かなり有用な機能なのではないでしょうか。
実際に使う場合は、まずはUnivariate analysisとCorrelation matrixとBivarate analysisあたりを使って傾向をおさえておけばよさそうです。
さらにデータから得られた仮説の検証のためには、Fit curves & distributionsで母集団の確率分布にあたりをつけつつ、それに適した手法をStatistical testsで用いる、といった使い方になりそうですね。