1.はじめに
1.1.背景
先日、「AWS上に検証環境を作って,バーチャルアプライアンス(FortiManager,FortiAnalyzer)の機能検証をしてほしい」とお願いされました.
恥ずかしながら当時の私はバーチャルアプライアンスのことはおろかAWSのことさえほぼ何も知らず、分からない単語だらけのミッションだったのですが,周囲の方々の協力のおかげでどうにか形になってきました。
試行錯誤の過程で、知らないとハマってしまうであろうポイントがいくつか出てきたため、アウトプットも兼ねて皆さんとナレッジを共有させていただきたいと思います.
本記事では機能検証の内容そのものではなく、その前段であるAWS上に検証環境を構築する方法に焦点を絞って解説したいと思います。
機能検証の内容自体については、またいずれ別記事でまとめる予定ですので、興味がある方は是非そちらもご覧ください。
今回はFortinet社のバーチャルアプライアンスを用いていますが、もちろん他ベンダーの様々なアプライアンスにも応用可能な内容だと思いますので、もしも皆さんが同じようなことをする際は、少しでも参考にしていただければ幸いです.
また,「他にもやり方あるよ!」「自分はこんな感じでやってるよ!」という方がいらっしゃれば,是非ともコメントでご教授いただければと思います.
1.2.対象読者
AWS初心者の方で、「興味はあるけど何をしたらいいか分からない」「本やドキュメントなどでAWSについて一通り勉強したけど、実際どんな風に使ってみたらいいか分からない」といった方のイメージをつかむ一助になれればと思います。
私自身もまだまだ初心者のため、「既にAWSをバリバリ使ってるよー」というベテランの方には冗長な表現や不完全な部分もあるかと思いますが、そのあたりはご容赦ください。
ちょいちょい出てくるAWSのサービス名や機能などは出来るだけリンク化して、そのサービスに関するAWSの公式ドキュメントに飛べるようにしてあるので、もっと詳しく知りたい方はそちらも併せてご覧ください。
また現在進行形でアプライアンスの検証などをオンプレで行っているというインフラエンジニアの方は、是非今後の選択肢の一つにしていただければと思います。
2.クラウド(AWS)上に検証環境を構築するメリット・デメリット
新米エンジニアなりに考えて書いたものですが、少し長くなってしまったので別記事にまとめてあります。
インフラエンジニアの方以外にはあまり関係ない内容かもしれませんが、もし興味をお持ちいただけましたら是非ご一読ください。
クラウド(AWS)上に検証環境を構築するメリット・デメリットまとめ
3.検証対象
まず、今回の検証対象アプライアンスである
- FortiManager
- FortiAnalyzer
について簡単にご説明します。
私も今回依頼されるまで全く見識がありませんでした。
これらは、アメリカのセキュリティベンダー大手であるFortinet社が展開している製品群の内の一つです。
FortiGateという、同社の販売しているファイアウォールがあるのですが、FortiManager・FortiAnalyzerは、これを管理・監視するための補助的なアプライアンスという位置づけになります。
それぞれ非常に多岐にわたる便利な機能がある(らしい)のですが、少なくとも今回の検証では、
- FortiGate=ここに来た通信を事前に設定したポリシー(ルール)によって通すか通さないか決めるアプライアンス(一般的なファイアウォールのイメージ)
- FortiManager=複数のFortiGateを一元的に管理するためのアプライアンス
- FortiAnalyzer=各FortiGateに来た通信のログをまとめて解析するためのアプライアンス
といった程度の理解でまず支障ありません。
各アプライアンスの機能に関する詳細な説明については、申し訳ありませんが本題から外れてしまうので今回は割愛させていただきます。
いずれまとめるかもしれませんし、まとめないかもしれません(笑)
今回の検証の目的は、FortiManager・FortiAnalyzerの大雑把な使用感を知ることです。
割とマイナーな製品であるため社内にもノウハウを持つ人が少なく、顧客に提案しようにも実際これがどういうものなのかが分からないため、とりあえず試しに検証してみてほしいとのことでした。
ですがマイナーすぎて社内に検証用の実機すら無かったため、ライセンスだけ取得してAWS上にバーチャルアプライアンスを展開し、それを利用して検証を行ってみよう、といった運びになったのが始まりです。
4.検証環境構築
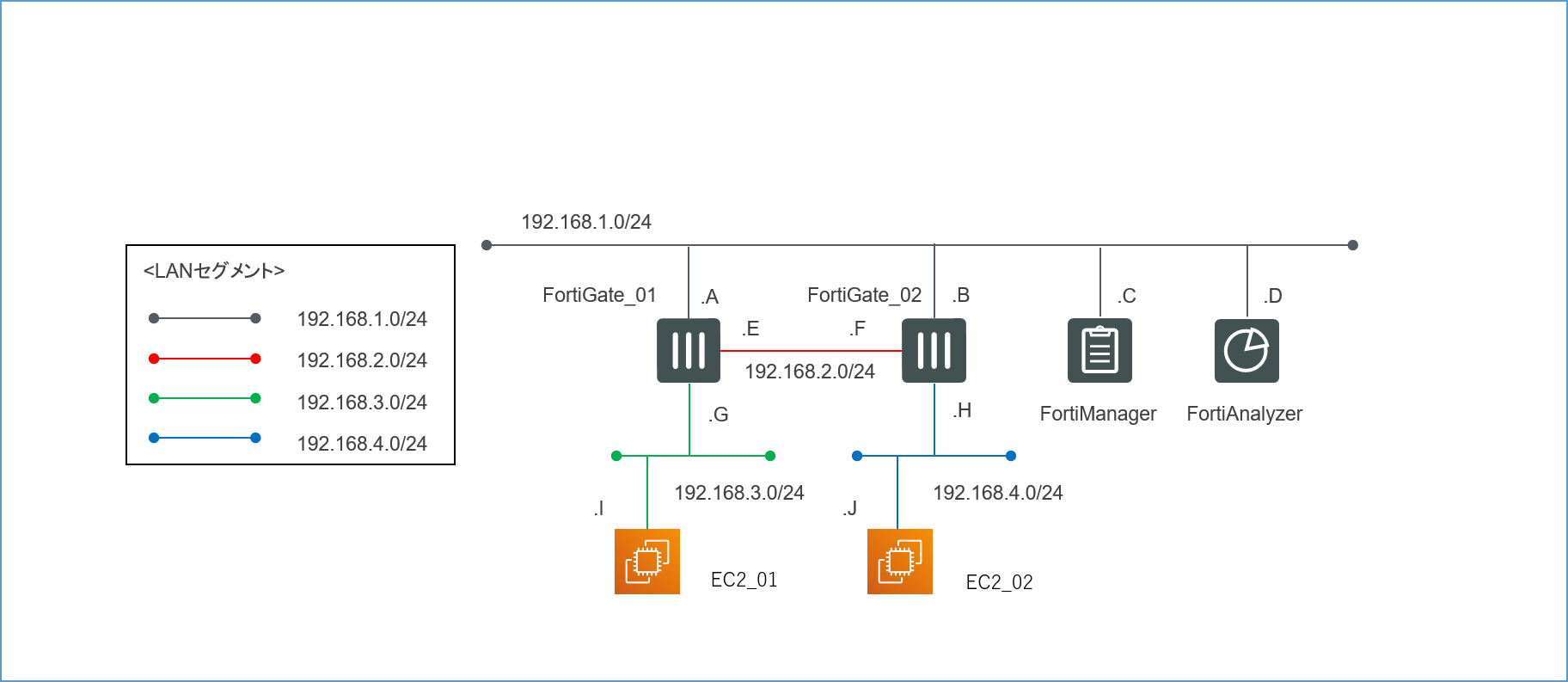
4.1.論理構成
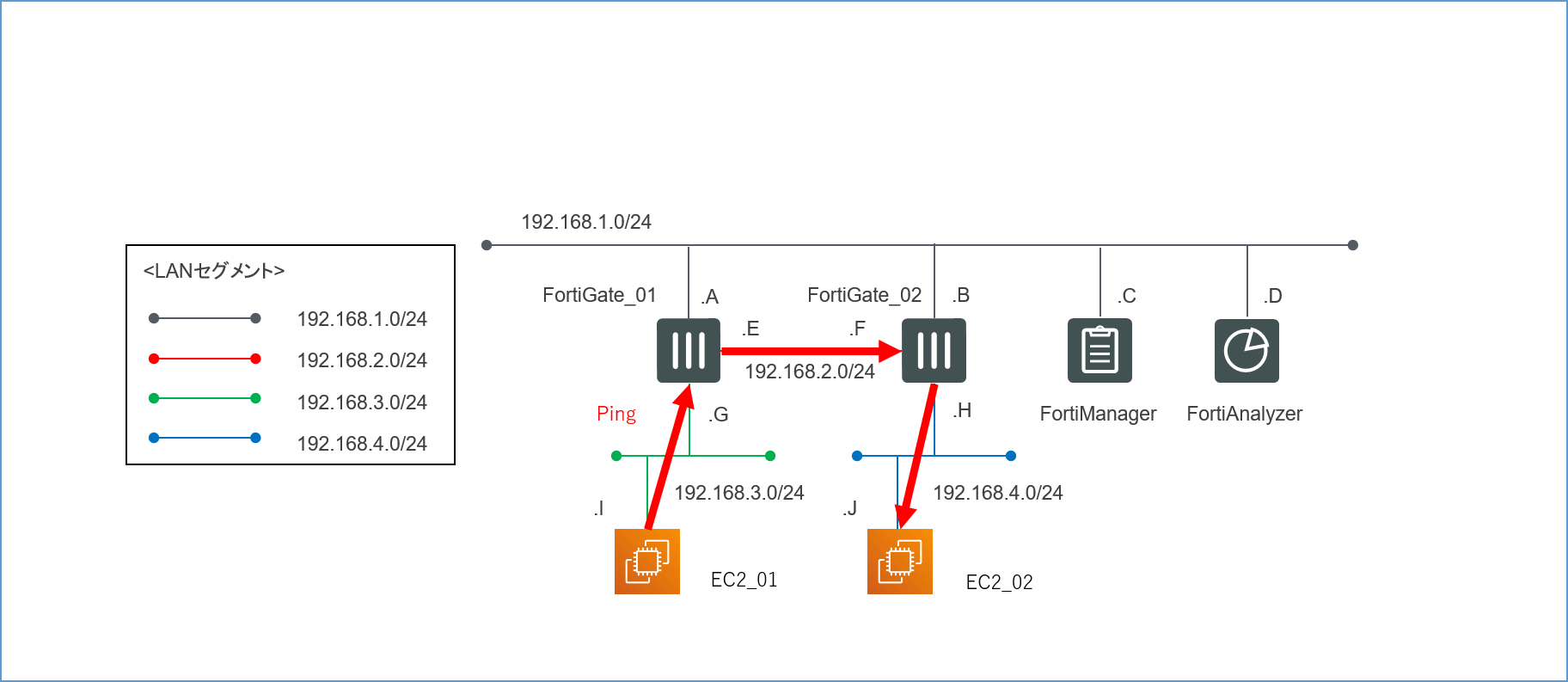
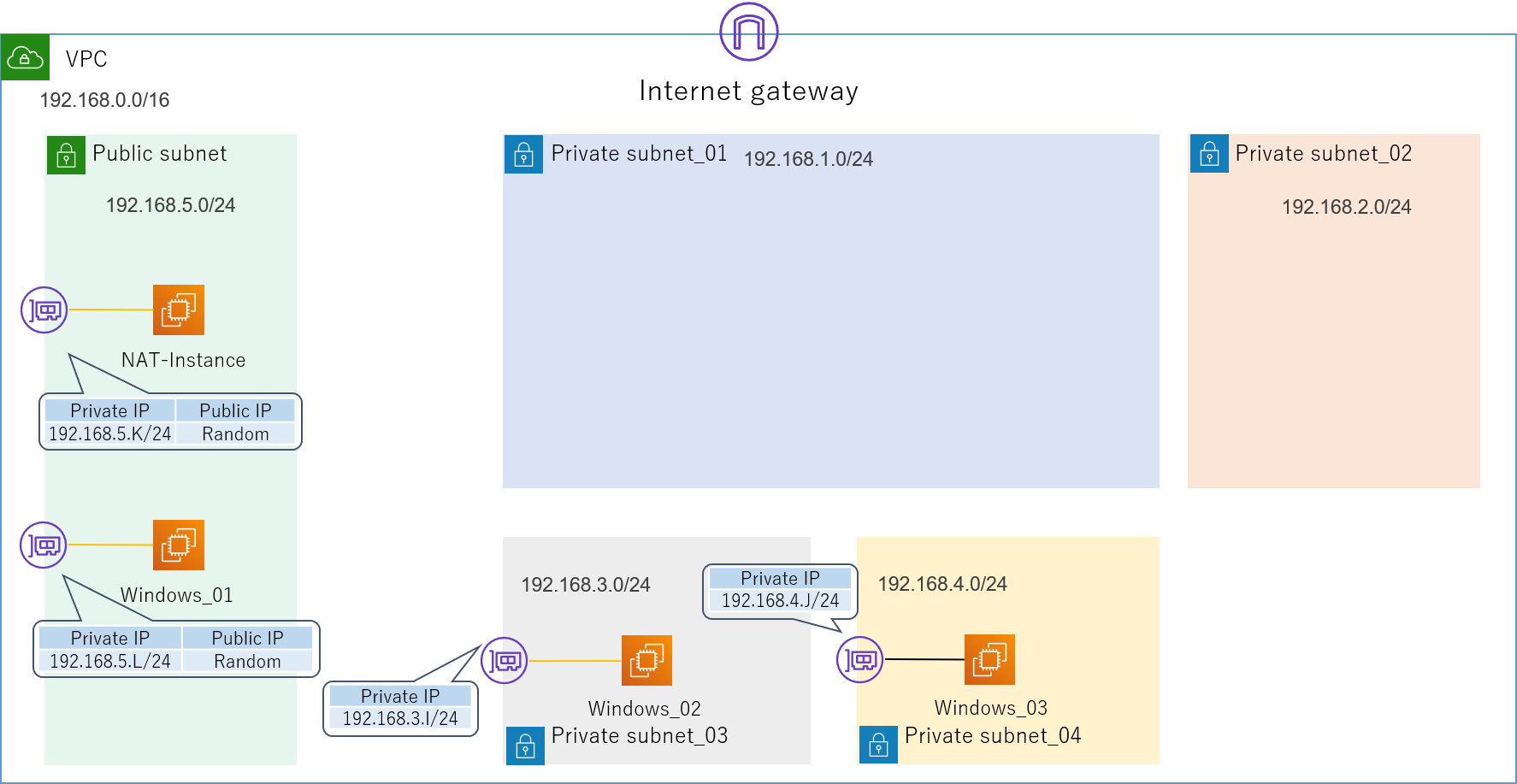
とりあえずこのような論理構成図を作成してみました。
![論理構成図.png]()
4つのセグメントで構成された、非常にシンプルなLANです。
192.168.1.0/24が管理セグメントになります。
各インターフェースに振るIPアドレスは基本的に何でもいいのですが(0,1,2,3,255の5つはAWS側で予約されているため使えません)、本記事では分かりやすくするため第4オクテットはアルファベットで表記してあります。
送信元の検証用サーバーEC2_01からの通信がFortiGate_01とFortiGate_02を経由して、宛先の検証用サーバーEC2_02に到達するような経路を想定しています。
![論理構成図_01_想定経路.png]()
最初の目標は、とりあえずこの経路で無事にPingの疎通が取れることを確認することです。
無事に検証環境が構築できたら、この構成を使って以下の2つの検証を行っていきます。
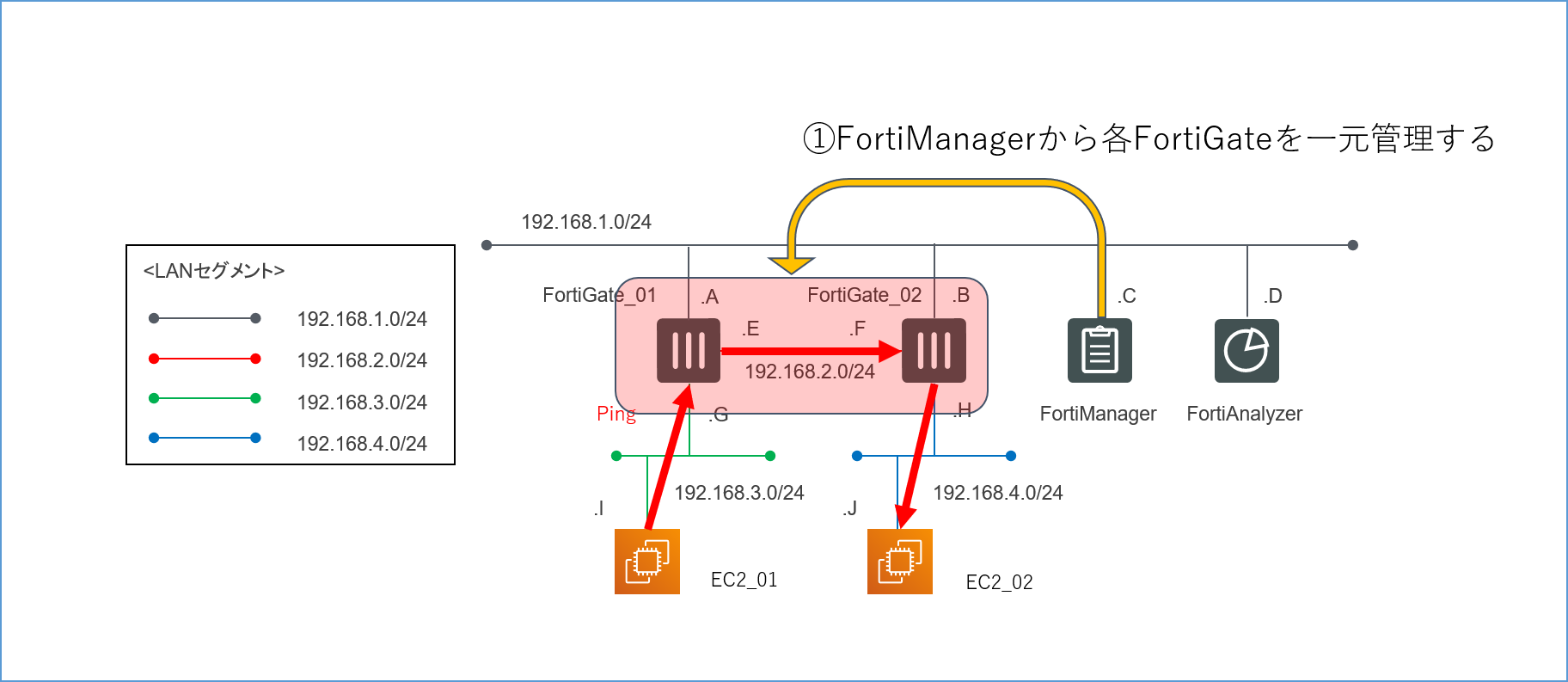
4.1.1.各FortiGateのポリシーがFortiManagerで一元管理できるか
![論理構成図_検証1.png]()
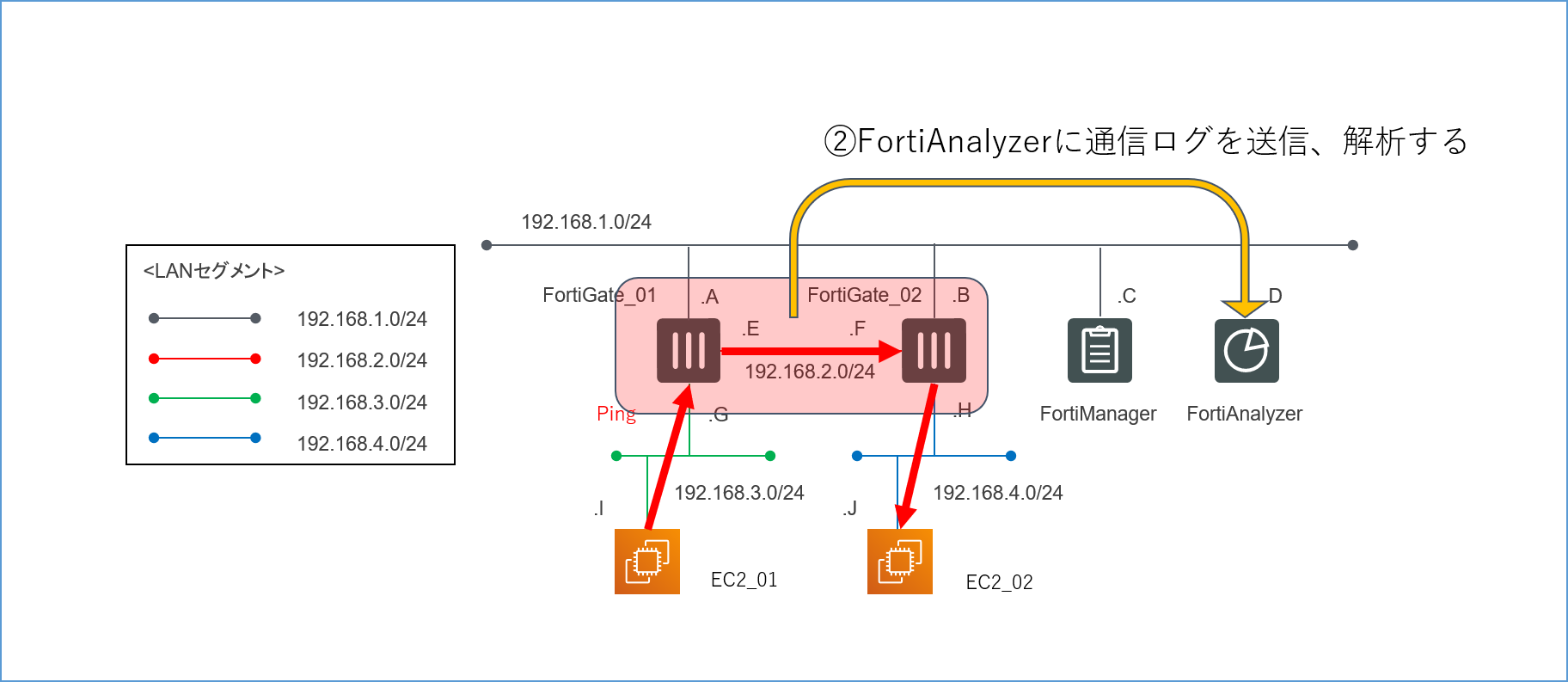
4.1.2.FortiGateを通過した通信についてのログをFortiAnalyzerに転送し、解析できるか
![論理構成図_検証2.png]()
4.2.AWSコンポーネント
それではまず先ほどの論理構成図を一つずつAWSのコンポーネントで構築していきます。
AWS初心者の方でもなるべく理解しやすいよう丁寧に説明していく予定ですが、流石にAWSの各サービスやインスタンスの具体的な作成手順に関してまでは、そこまで詳細な説明を行えません(とんでもない分量になってしまいます)。
なので詳しくは公式ドキュメントを参照したり、実際にAWSコンソールで手を動かしてみてください。
また、今回はあくまで検証環境ということで、リージョンやAZ(アベイラビリティーゾーン)にも特にこだわりませんのでご了承ください。
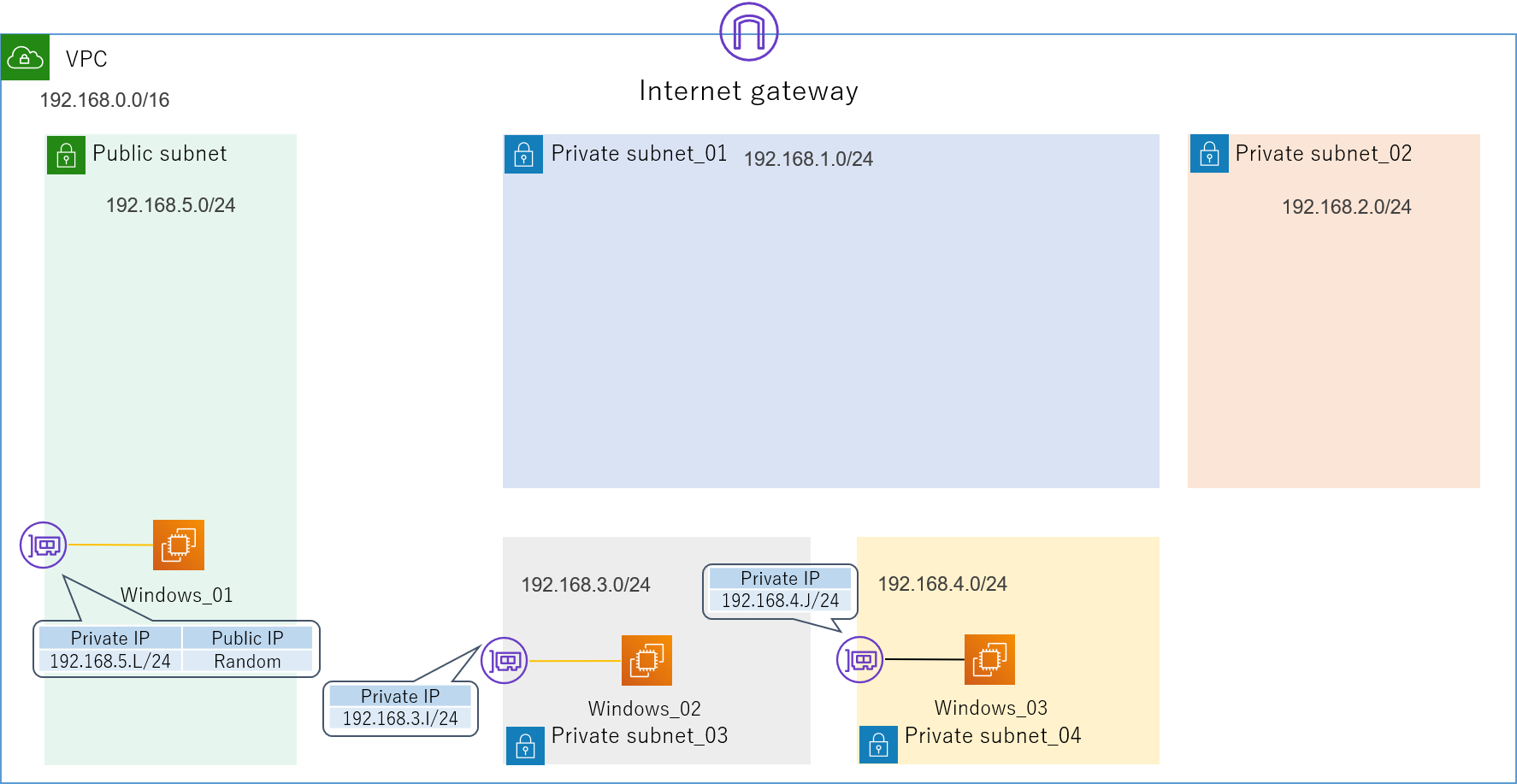
4.2.1.VPC
まずはVPC(Virtual Private Cloud)を用意します。
構築するネットワークの入れ物ですね。
今回は192.168.0.0/16というIPv4 CIDRブロックを割り当てました。
![AWS構築過程_01_VPC.png]()
まだ、ただの箱です。
4.2.2.サブネット
続いて、この中にサブネットを作成します。
先ほどの論理構成図にあったセグメントの
- 192.168.1.0/24
- 192.168.2.0/24
- 192.168.3.0/24
- 192.168.4.0/24
をPrivate_subnetで、またインターネット接続用にPublic_subnetとして192.168.5.0/24を作成します。ついでに、VPCにはインターネットへの出入り口であるInternet Gatewayを取り付けます。
![AWS構築過程_02_サブネット.png]()
4.2.3.EC2の作成
いよいよサブネット内に配置するEC2インスタンスの作成に入ります。
4.2.3.1.踏み台サーバー、検証用サーバー
今回は踏み台サーバー(Windows_01)、検証用サーバー(Windows_02,Windows_03)ともに、OSにWindows Server 2019を使用します。
検証用サーバーのOSはLinuxでももちろん構いません。
検証用にWindowsサーバーを使用する場合は、OSのファイアウォールを解除しておくことを忘れないでください(ここでパケットが弾かれると結構気が付きにくいです)。
ここで同時にENI(Elastic Network Interface)の設定も行うため、インスタンスが所属するVPCやサブネット、IPアドレスを指定しましょう。
踏み台サーバーは外部からも接続するので、Private_IPだけでなくPublic_IPも必要です。
ちなみにPublic_IPの取得方法は
の2種類があります。今回は前者を利用します。
インスタンスの作成途中でセキュリティグループの設定も要求されると思います。
これはざっくり言うと各インスタンスが持つ仮想のファイアウォールのことなのですが、ここはかなり大事なのできちんとドキュメントを読んで勉強することをお勧めします。
セキュリティに関する部分だけあって、取り扱いをミスると色々と実害を被りかねないので。
少なくとも踏み台サーバーはRDPやSSHなど必要最低限のサービスだけを有効にして、接続元も社内ネットワーク限定などにしておくのをお勧めします(使用ポートの変更もしておければなおいいです)。
他にも使用する予定のプロトコルやサービスがあるなら、ここで事前に許可設定を入れておかないと、何もできないインスタンスになってしまうので注意してください。
「なぜかインスタンスにアクセスできないなー」って時は大体ここのせいな気がします。
![AWS構築過程_03_EC2_01.png]()
4.2.3.2.NATインスタンス
Private_subnetから外部のインターネットに接続するためには、NATゲートウェイもしくはNATインスタンスが必要です。
NATゲートウェイは高機能で楽ですが少々コストが高いので、今回はNATインスタンスを使います。
Private_subnet内のインスタンスがインターネットに出る際は、まずこのNATインスタンスにルーティングされ、NATインスタンスが持つPublic_IPに変換されてから外部に接続します。
![AWS構築過程_04_EC2_02.png]()
4.2.3.3.バーチャルアプライアンス
それでは今回のメインインスタンスである、バーチャルアプライアンスを作成していきます。
AWSでは、AWSMarketPlaceというオンラインストアで様々なベンダーのバーチャルアプライアンスが展開されています。
Fortinet社のバーチャルアプライアンスも一通り揃っていますので、ここから必要なものを探しましょう。
アプライアンスの利用形態には、
- ソフトウェア料金が込み
- BYOL(Bring Your Own License)
の2種類が存在します。
前者は通常のEC2の使用料金にソフトウェアの使用料が上乗せされているもので、通常のEC2のように従量課金で使えます。
それに対して後者のBYOLというのは、ソフトウェアのライセンスを自前で用意しておけば、後はEC2の使用料のみで使うことができるというものです。
当然ライセンスさえ用意出来るなら後者の方が遥かに安くすみます。
今回は既にライセンスは準備済みなので後者の方法で作成していきます。
基本的な作成手順は通常のEC2と何ら変わりません。
ちなみにBYOLで作成する場合、ライセンスはこの段階で要求されることはありません。
途中で一つ管理用にENIを作らされますが、論理構成図から分かるように今回FortiGateではそれぞれ3つのENIが必要になるので、2個ずつ追加で増やします。
各ENIの所属するサブネットを間違えないようにしてください。
また、ここで非常に重要なのが送信元/送信先の変更チェックという機能を無効にしておくことです!
というのも、AWSインスタンスののENIは、デフォルトで自分のIPアドレス宛のパケット以外を全て自動的に破棄してしまいます。そのため、今回のFortiGateのように複数のENIを持つインスタンスを作ってパケットの中継地点として利用しようとしても、この機能を無効化しない限り全くルーティングされません。
AWSコンソールにて、インスタンスを右クリック→ネットワーキングで設定できます。
私はこれになかなか気づけず、だいぶ時間を浪費してしまいましたので、皆さんはご注意ください。
セキュリティグループはアプライアンス側がデフォルトのものを用意してくれていますので、基本的にはそれで問題ないと思います。
もちろん何か変更を加えるのもありです。
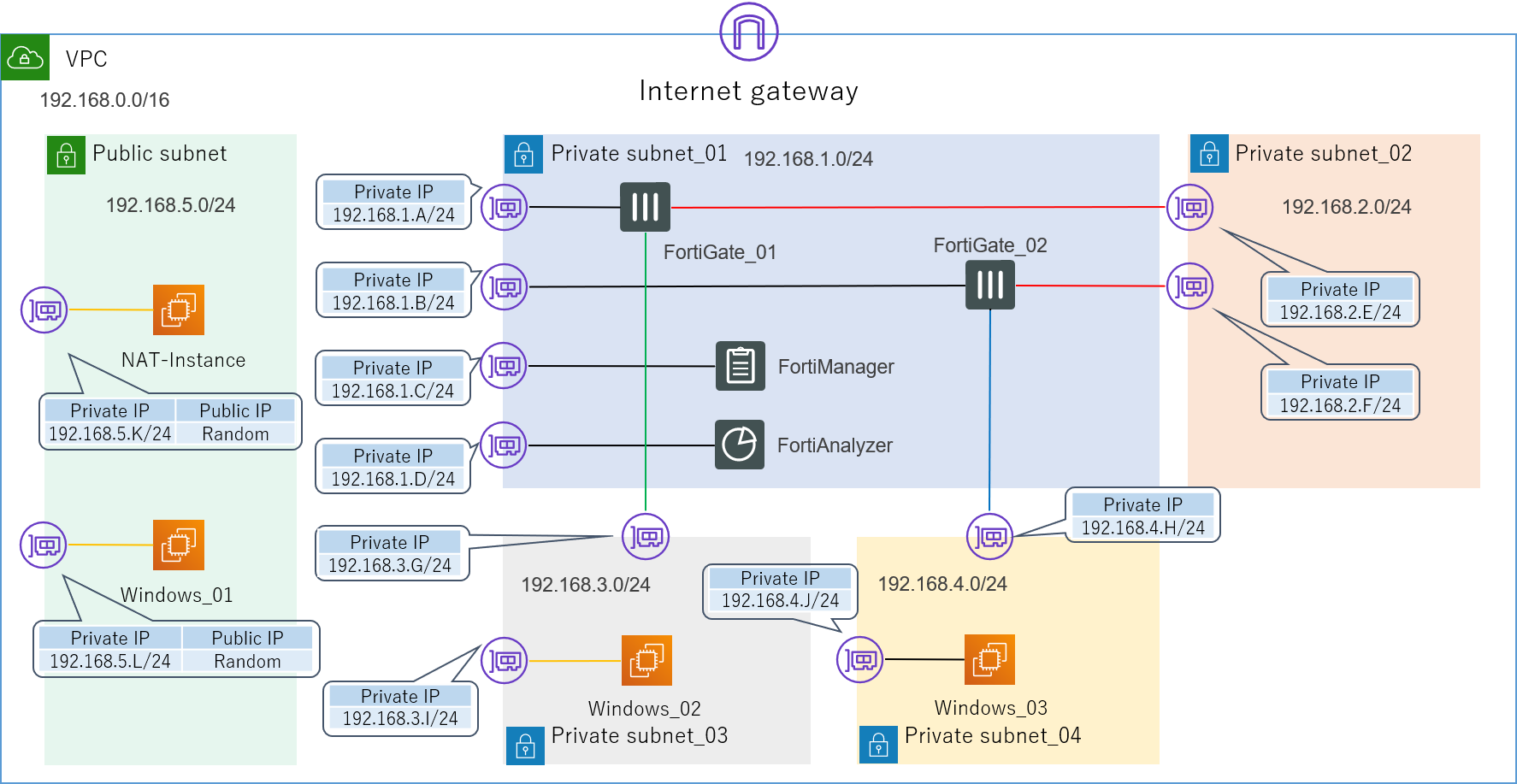
以上でひとまずAWSの構成が完成しました(見た目上は)。
AWS構成図
![AWS構成図.png]()
4.3.バーチャルアプライアンス
続いて、バーチャルアプライアンス内部の設定を進めていきます。
4.3.1.ライセンス認証(BYOLのみ)
今回はBYOLなので、まずはバーチャルアプライアンスのライセンス認証をする必要があります。
まずはRDPで踏み台サーバーにログインし、ブラウザとターミナルソフトをインストールしておきましょう。
Windowsサーバーだと、サーバーマネージャーからソフトウェアをインストールできるように設定しておく必要があるかもしれません。
私はGoogle Chromeとteratermを入れていますが、別に他のものでも十分代用可能です。
ブラウザを開いたら、先ほど設定したFortiGateの管理用IPアドレスにアクセスします。
設定が全て上手くいっていれば、FortiGateのGUI管理画面にアクセスできます。
途中で危ないとかなんとか言われても全て無視してください。
最初は
- 初期ユーザー名:admin
- 初期パスワード:自身のインスタンスID
でログインするよう指示されます。
一度ログインしたらパスワードはすぐに変更させられますので、適当なものを考えておいてください(8文字以下だと怒られます)。
ログインに成功するとここでようやくライセンスを要求されるので、あらかじめ用意しておいたライセンスをアップロードします。
ちなみに私が試したところ、一回目はなぜか弾かれるのですが、二回目はすんなり通りましたので、一度失敗したからと言ってすぐに諦めないでください。
ライセンスのアップロードに成功すると、ようやくFortiGateが使用可能な状態になります。
FortiManager,FortiAnalyzerもここまでは全く同じなので同様に進めておきましょう。
全て使えるようになったら、各アプライアンスのGUI画面をブックマークしておくとあとあと楽です。
ブラウザのタブで色々なアプライアンスを同時に管理出来るのは便利ですよ。
4.3.2.インターフェース作成と関連付け
次はFortiGateのインターフェースを作成し、AWSのENIと関連付けしていきます。
まずはFortiGateのGUIからNetwork>Interfaceに移動し、新規インターフェースを3つ作成しましょう。
名前は何でもいいですが、今回はPort 番号にしたいと思います。
タイプはもちろん物理インターフェースです(バーチャルアプライアンスですが)。
アドレッシングモード(インターフェースに割り当てるIPアドレスを決める方法)の設定では、DHCPを選択してください。
この設定にすると、自動的にFortiGate内部のインターフェースとAWSのENIが関連付けされます。
ちなみにマニュアルを選択して手動でIPアドレスを入力すると失敗します。
私はこれをやってしまい、結構ドはまりしました。
設定した見た目はどちらも同じなのですが、マニュアルだとインターフェースがENIと関連付けされないため、使えません。
管理者アクセスは、各インターフェースにアクセスできるサービスを設定できます。
最低でも管理インターフェースであるPort1にはSSH、HTTPS、FMGアクセスを、Ping用のポートであるPort2、Port3にはPINGを許可しておきましょう。
ちなみにFMGアクセスというのは、FortiManagerに管理してもらう時に必要となります。
インターフェースがこのように設定できたら成功です。
FortiGate_01
| Name | Type | IP Adress/Mask | 管理者アクセス |
|---|
| Port1 | 物理インターフェース | 192.168.1.A | SSH,HTTPS,FMGアクセス |
| Port2 | 物理インターフェース | 192.168.2.E | PING |
| Port3 | 物理インターフェース | 192.168.3.G | PING |
FortiGate_02
| Name | Type | IP Adress/Mask | 管理者アクセス |
|---|
| Port1 | 物理インターフェース | 192.168.1.B | SSH,HTTPS,FMGアクセス |
| Port2 | 物理インターフェース | 192.168.2.F | PING |
| Port3 | 物理インターフェース | 192.168.3.H | PING |
4.3.3.スタティックルート作成
インターフェースを作成したら、Network>Static Routeから対向のFortiGateに向けてスタティックルートを設定します。
有効化するのを忘れないようにしてください。
FortiGate_01
| Destination | Gateway IP | Interface |
|---|
| 192.168.4.0 | 192.168.2.F | Port2 |
FortiGate_02
| Destination | Gateway IP | Interface |
|---|
| 192.168.3.0 | 192.168.2.E | Port2 |
4.3.4.ポリシー作成
いよいよFortiGateのメイン機能です。
Policy&Object>IPv4 Policyから設定します。
ACL(Access Control List)とほとんど仕組みは同じで、基本的には全てImplicit Deny(暗黙の拒否)となっており、許可したい通信の設定のみを一つ一つ登録していくような感じです。
最終的にはこのポリシーをFortiManagerから一括で制御するのが目標ですが、とりあえず最初は疎通確認のために各FortiGateに適当なポリシーをあらかじめ入れておきます。
FortiGateのポリシーは様々な項目を設定できるのですが、とりあえず今はPingが通りさえすればいいので以下のように設定しました。
FortiGate_01
| Name | 着信インターフェース | 発信インターフェース | 送信元 | 宛先 | サービス | アクション |
|---|
| 3_to_2 | Port3 | Port2 | all | all | All ICMP | ACCEPT |
| 2_to_3 | Port2 | Port3 | all | all | All ICMP | ACCEPT |
| Implicit Deny | All | All | all | all | All | DENY |
FortiGate_02
| Name | 着信インターフェース | 発信インターフェース | 送信元 | 宛先 | サービス | アクション |
|---|
| 3_to_2 | Port3 | Port2 | all | all | All ICMP | ACCEPT |
| 2_to_3 | Port2 | Port3 | all | all | All ICMP | ACCEPT |
| Implicit Deny | All | All | all | all | All | DENY |
これでFortiGateの設定は全て完了です。
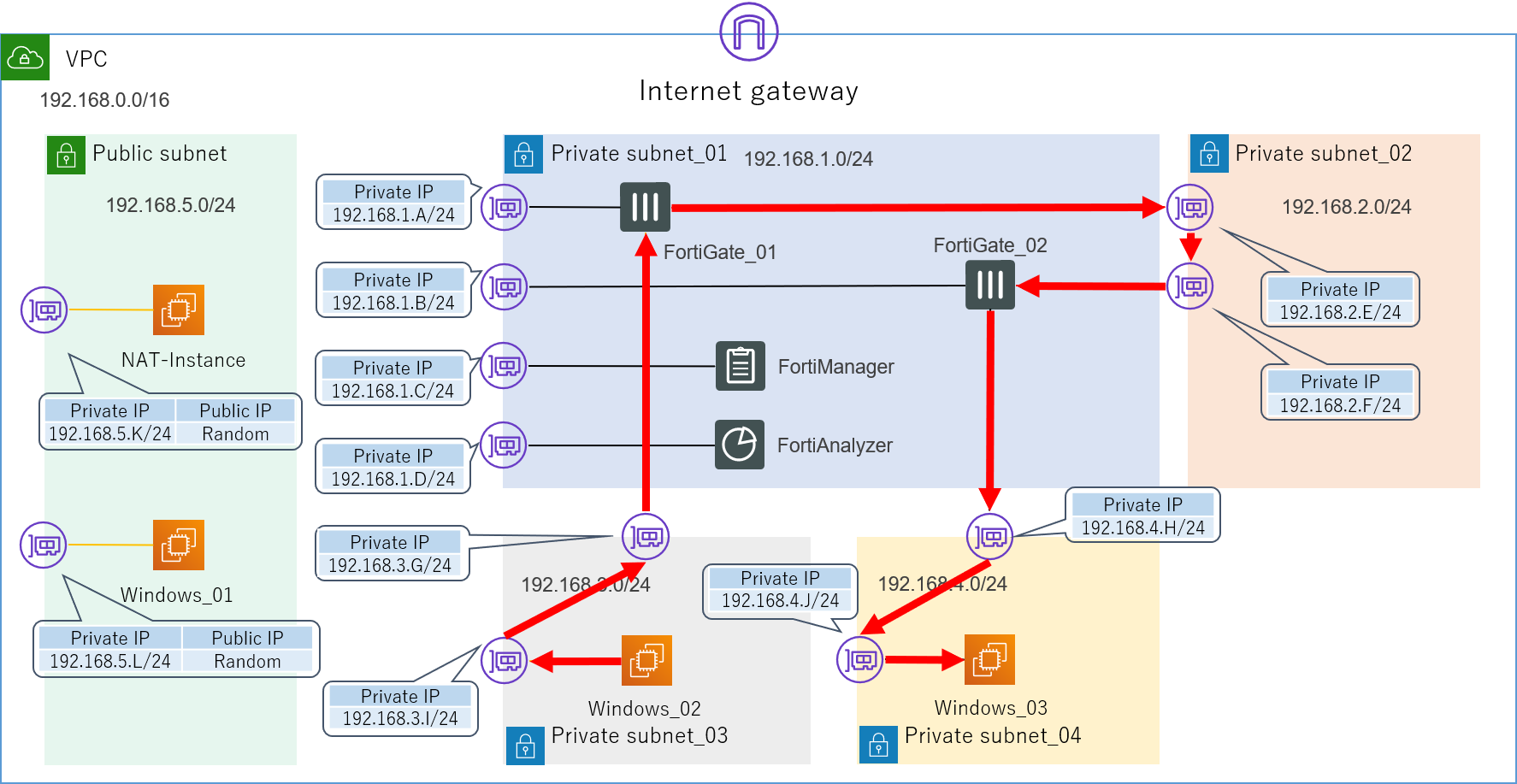
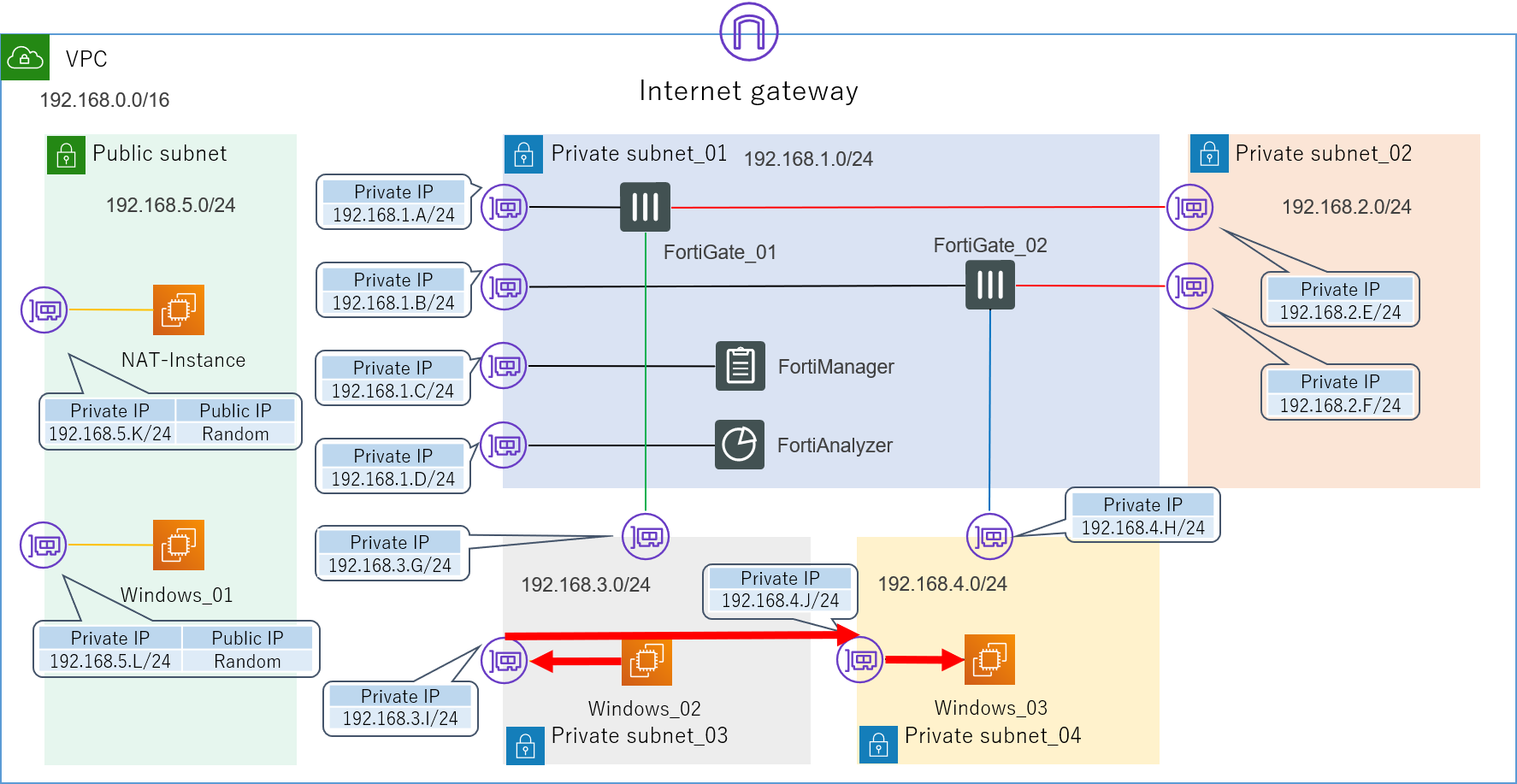
ですが、実はここまでしてもまだ想定した経路の通信は実現できません。
正確に言えば、この状態でWindows_02からWindows_03に向けてPingを打つと疎通自体は確認できてしまうのですが、実はそれは以下の想定経路ではなく、実際の経路の図に示すように、せっかく色々と頑張って設定したFortiGateを完全に無視したものとなっています。
想定経路
![AWS構成図_02_想定経路.png]()
実際の経路
![AWS構成図_03_実際の経路.png]()
4.4.ルートテーブル
なぜこのような挙動になってしまうかといいますと、全てAWSのルートテーブルが原因です。
詳しくはAWSの公式ドキュメントをご参照いただければと思いますが、簡単に言えば、ルートテーブルとはVPC内に存在する暗黙的なルーターのことです。
VPC内の通信は、全てこのルートテーブルによって定義されます。
先ほどの構成において、現在使用しているルートテーブルは以下のようになっています。
Main Route Table(4つのPrivate_subnet全てに関連付け)
| Destination | Target |
|---|
| 192.168.0.0/16 | local |
| 0.0.0.0/0 | NATインスタンス |
Public Route Table(Public_subnetに関連付け)
| Destination | Target |
|---|
| 192.168.0.0/16 | local |
| 0.0.0.0/0 | Internet Gateway |
このlocalの意味ですが、これはこのVPC内の通信(192.168.0.0/16に属する通信)は、全て自動的に直接宛先のENI(NIC)にルーティングされるということを示しています。
これはデフォルトで入っているもので、編集も削除もできません。
また、それ以外の通信(0.0.0.0/0)は全て外部インターネットにルーティングするように追加で設定しています。
このルートテーブルのおかげで、私たちは各インスタンスの細かいルーティング設定を全く意識することなく、簡単に通信を行えるようになっています。
とても効率的で大変ありがたいのですが、しかし今回のアプライアンス検証という目的を考えるとそれでは困ります。
実はこのVPC内のサブネット間の通信をもっと自由に制御する方法を探すというのが、今回の検証環境構築の一番の肝でした。
4.4.1.NG集
正解に入る前に、試行錯誤から生まれた失敗例を少しご紹介しておきたいと思います。
皆さんは同じ失敗をしないでください。
4.4.1.1.VPCのルートテーブルで制御する→失敗
まず最初に私が試した方法は、単純にこのルートテーブルに更に詳細なルートを追加して各サブネットにアタッチしてみるというものでした。
通常のネットワーク機器なら、ロンゲストマッチでこのルートを使ってくれるはずですよね。
Main Route Table(ルート追加の例)
| Destination | Target |
|---|
| 192.168.0.0/16 | local |
| 192.168.4.0/24 | 192.168.3.G |
| 0.0.0.0/0 | NATインスタンス |
しかし結論から言うとこの方法は失敗でした。
どうやらルートテーブルのルールとして、192.168.0.0/16→localよりも詳細な指定をするルートを追加することは出来ないようです。
正確に言うと、そのようなルートを追加したルートテーブルを作成すること自体は可能なのですが、それをサブネットにアタッチしようとするとエラーで弾かれてしまいます。
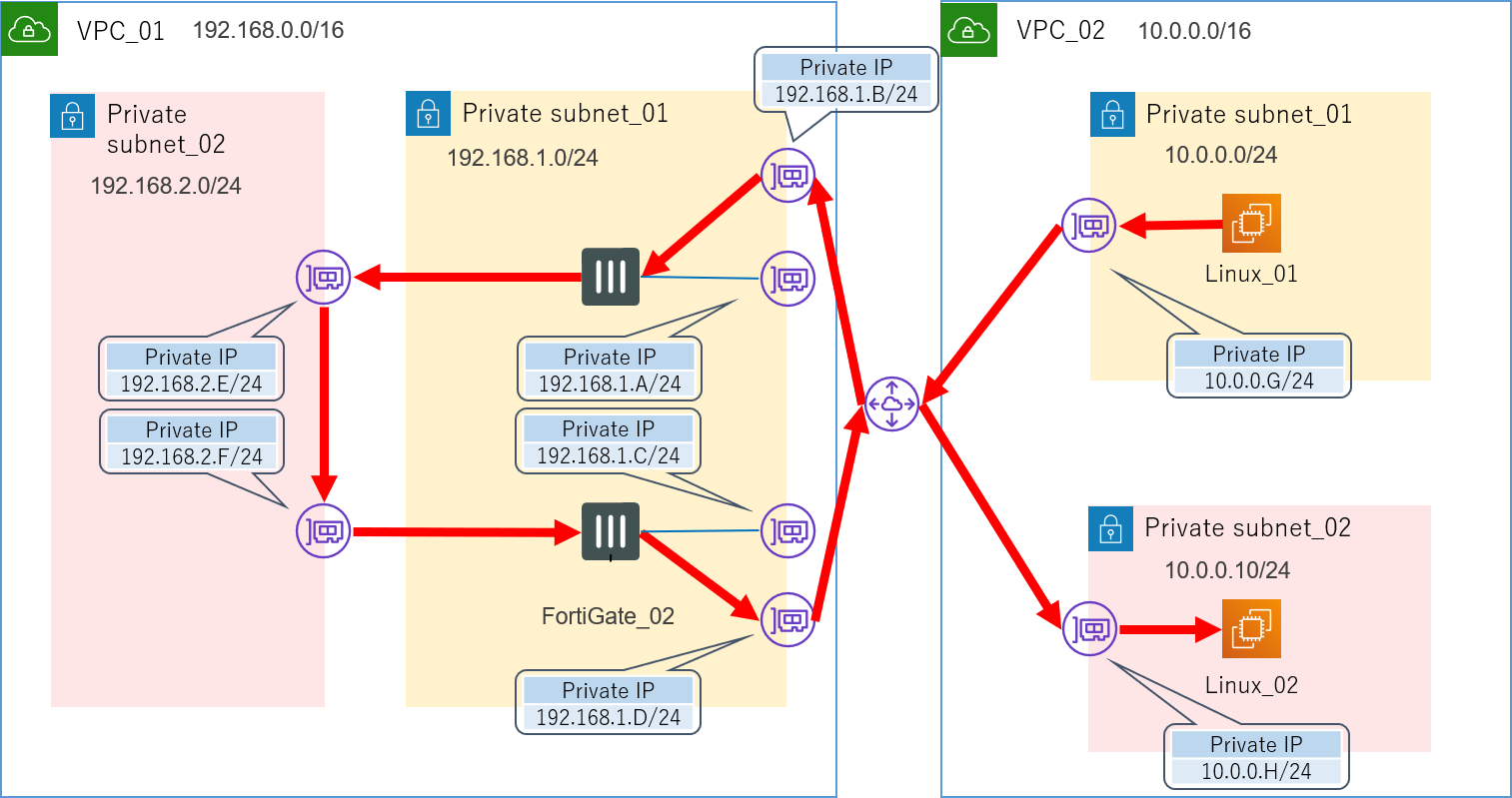
4.4.1.2.VPCピアリングを利用してみる→失敗
AWSには異なるVPC同士を繋ぐことのできる、VPCピアリングというサービスが存在します。
「同一VPC内では細かいルーティング制御ができないというなら、VPCごと分けてしまえばいいじゃない」といった発想でこれも試してみることにしました。
このサービスを利用するにあたり、少し構成も変更しました。
が、これも失敗です。
VPCピアリングを利用した構成
![AWS構成図_04_VPCピアリング.png]()
VPCピアリングでつながる関係というのは、異なるルートで行ったり来たりは出来ないようです。
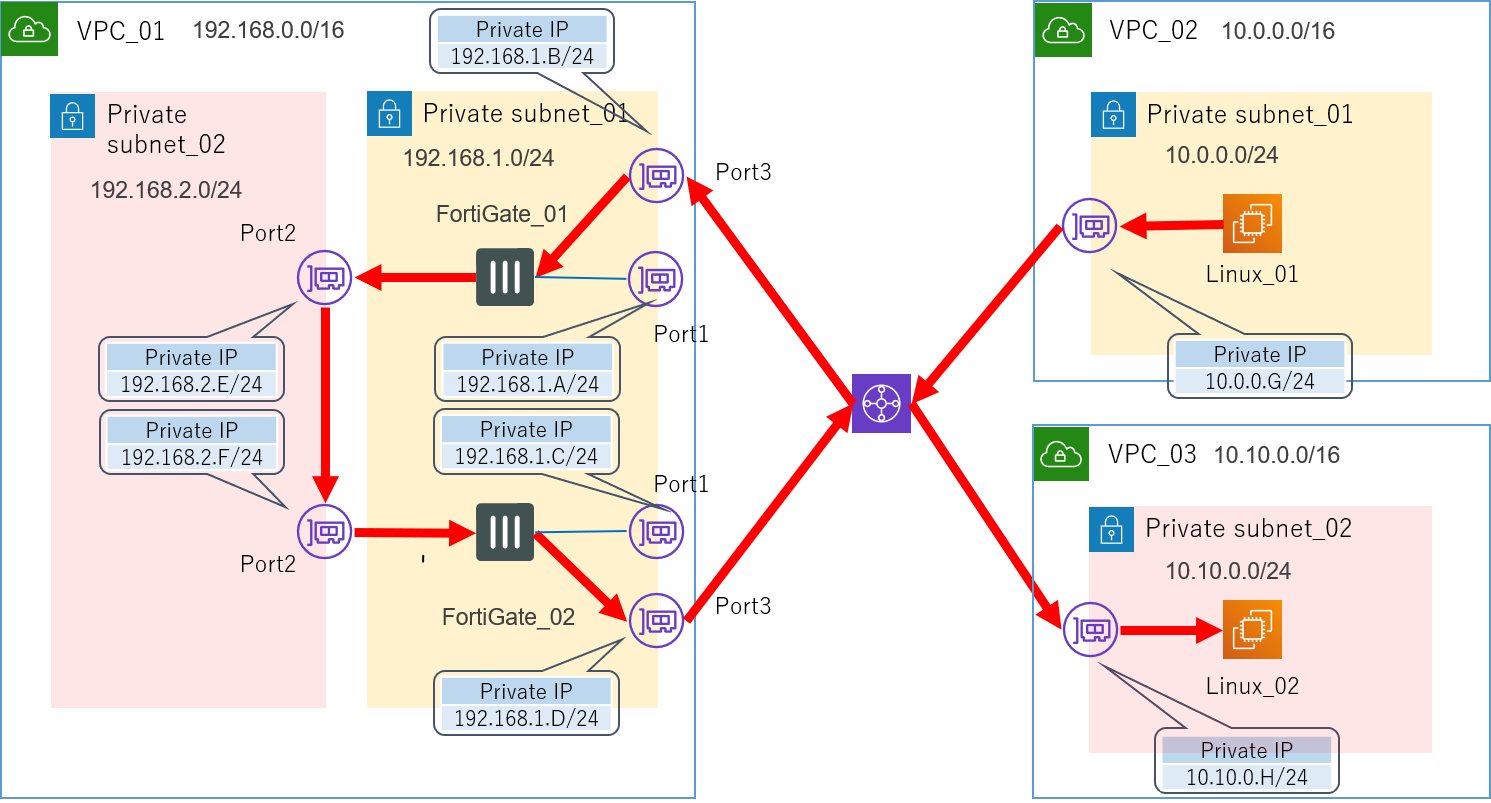
4.4.1.3.Transit Gatewayを利用してみる→?
この方法に関しては、もしかすると上手くいくのかもしれません。
が、この方法を試す前に正解を見つけてしまったというのと、このサービスを利用するのには少々コストがかかりそうだというので、実は今回はあまり深く検証していません。
AWSの方に問い合わせたところ、「Ingress Routingという機能を利用すれば可能だと思われる」いった回答は頂いています。
もし興味をお持ちになられた方、もしくは既に試したことがあるという方がいらっしゃいましたら、是非情報提供よろしくお願いします。
Transit Gatewayというのは、最近東京リージョンでも利用可能になったばかりの新しいサービスです。
従来VPC間を繋ぐためには先ほど紹介したVPCピアリングが一般的でしたが、これは推移的なピア関係をサポートしていませんでした。
例えるなら、友達の友達は友達ではないといった感じですかね。
なので複数のVPC同士を接続するためには、どうしてもフルメッシュ構造をとるしかありませんでした。
そこで登場したのが、ハブ&スポーク構造を実現できるTransit Gatewayです。
これを介することにより、複数のVPC間をシンプルに行き来できるようになりました。
先ほどのVPCピアリングではダメだったので、これを使えば上手くいくのではないかと一応構成だけは考えてみました。
Transit Gatewayを利用した構成
![AWS構成図_05_TransitGateway.png]()
Pingを打つためのサーバーを一つ置くためだけにVPCを一つ作るという何とも大げさな構成です。
ですがこれを試す前に正解の方法が見つかりました。
この方法でも上手くいくのか気になる方は是非ご自身で試してみてください。
4.4.2.OSのレイヤーでルーティングする→成功
どうやら各サーバーのOSのレイヤーでルーティングテーブルを書き換えてしまえば、ルートテーブルよりそちらが優先されるようです。
今回はWindows Serverを使用しているので、各Ping要員サーバーに入ってコマンドプロンプトからOSの持つルーティングテーブルを確認し、ネクストホップを追加しました。
ちなみに-pを付けないと再起動するたびにルーティングテーブルがリセットされてしまいます。
追加したらroute printでちゃんと入っているか確認してみてください。
Windows_02(192.168.3.I)にルートを追加
route add 192.268.4.0 mask 255.255.255.0 192.168.3.G -p
Windows_03(192.168.4.J)にルートを追加
route add 192.268.3.0 mask 255.255.255.0 192.168.4.H -p
ついに、無事に想定通りの経路でパケットがルーティングされるようになりました。
Tracertコマンドで確認しても、ちゃんと機能していることが確認できます。
これにて検証環境の構築は完了です。
お疲れ様でした。
5.チェック項目
それでは今までの経緯を踏まえて、AWS上に検証環境を構築する際に気を付けなければいけないことについてまとめておきたいと思います。
疎通確認が取れない時は参考にしてください。
- VPC
- サブネットは適切に設定されているか
- ルートテーブルは適切に設定されているか
- EC2
- パブリックIPアドレスは認識しているものと一致しているか(気が付かないうちに変わっている可能性あり)
- OSのファイアウォールは解除されているか(Windows Serverの時のみ)
- セキュリティグループは適切に設定されているか(これが一番ありがち)
- OSのルーティングテーブルは適切に設定されているか
- 送信元/送信先の変更チェックは適切に設定されているか
- FortiGate
- インターフェースはDHCPで設定されているか(マニュアルは×)
- 管理者アクセスは適切に設定されているか
- スタティックルートは適切に設定されているか
- ポリシーは適切に設定されているか
- その他
- AWSだけでなく、外部のネットワーク環境に問題はないか(あまり詳しくは言えないのですが、私はこの部分でも苦労しました)
- コストはちゃんと管理できているか
6.おわりに
いかがでしたでしょうか。
この環境を用いて行った機能検証の具体的な内容についても近いうちまとめる予定ですので、もしご興味をお持ちいただけましたら是非そちらもご覧ください。
今回はAWS初体験ということもあり非常に基本的なサービスに終始してしまいましたが、AWSにはまだまだ興味深いサービスや触ってみたい機能が数えきれないほどありますので、これからも色々と試して皆さんとナレッジを共有していければと思います。
また、もしこの記事を読んで少しでも興味をお持ちになった方がいらっしゃいましたら、是非ご自身でも試していただきたいと思います。
最後まで読んでいただき、ありがとうございました。
それでは、また。