はじめに
前回の記事
【Python】初めての データ分析・機械学習(Kaggle)
【Python】初めての データ分析・機械学習(Kaggle)〜Part2〜
に引き続き、Kaggleで比較的優しいコンペ「House Prices: Advanced Regression Techniques」に挑戦しました!
今回のコンペは、住宅に関する情報の変数をもとに、住宅の価格を推定するというもの。
しかし、この住宅に関する変数が80もあり、いきなり怖気付きました、、(笑)
「こんなのできるのか、、?」て思いつつ、今回もしっかり先人の知恵を借りました!笑
参考コード↓↓↓
大まかな流れは、以下のようになっています。
- 特徴エンジニアリング
- Imputing missing values欠損値の穴埋め
- Transformingデータ変換(log変換等)
- Label Encodingカテゴリカルデータのエンコード
- Box Cox Transformation : 正規分布に近づけさせるための変換
- Getting dummy variablesカテゴリカルデータを数値データへ
- モデリング(スタッキングアンサンブル学習)
- ベースモデル解析
- 第2モデル解析
そして、本記事では、 モデリングに焦点を当てていきます!
ですから、Kaggleのコンペの予測値まで出力するところまで行きます!!
前回の特徴エンジニアリングに関する記事はこちら↓↓↓
【Python】データ分析、機械学習実践(Kaggle)〜データ前処理編〜
1. ライブラリのインポート
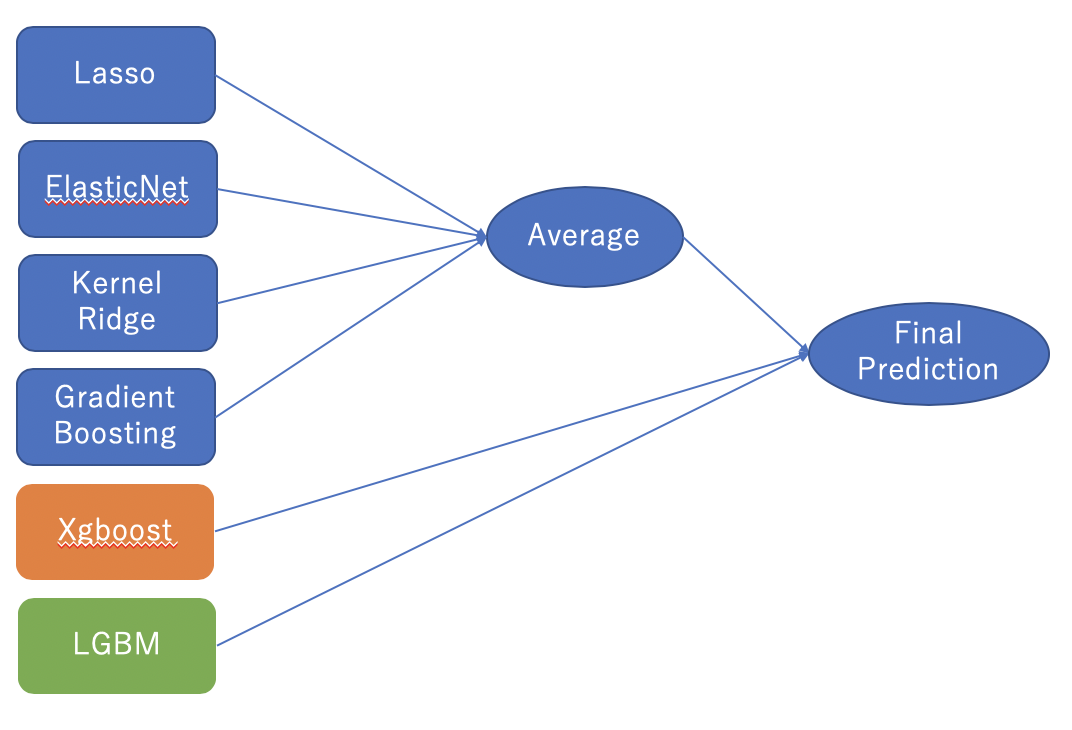
今回もTitanicの時と同様にスタッキングアンサンブル学習で予測する。
使用するモデル
1. LASSO Regression
2. Elastic Net Regression
3. Kernel Ridge Regression
4. Gradient Boosting Regression
5. XGBoost
6. LightGBM
学習の流れ
4つのモデルを平均する
- LASSO Regression
- Elastic Net Regression
- Kernel Ridge Regression
- Gradient Boosting Regression
1.で平均したモデルとXGBoostとLightGBMの3つでスタックして最終的な予測を行う
fromsklearn.linear_modelimportElasticNet,Lasso,BayesianRidge,LassoLarsICfromsklearn.ensembleimportRandomForestRegressor,GradientBoostingRegressorfromsklearn.kernel_ridgeimportKernelRidgefromsklearn.pipelineimportmake_pipelinefromsklearn.preprocessingimportRobustScalerfromsklearn.baseimportBaseEstimator,TransformerMixin,RegressorMixin,clonefromsklearn.model_selectionimportKFold,cross_val_score,train_test_splitfromsklearn.metricsimportmean_squared_errorimportxgboostasxgbimportlightgbmaslgb2. 交差検証の定義
k=5(データ群を5分割)として
モデルの評価は対数平均二乗誤差(RMSLE)で行います。
スコアが小さいほど精度が高いという見方です!
#Validation function
n_folds=5defrmsle_cv(model):kf=KFold(n_folds,shuffle=True,random_state=42).get_n_splits(train.values)#シャッフル
rmse=np.sqrt(-cross_val_score(model,train.values,y_train,scoring="neg_mean_squared_error",cv=kf))return(rmse)defrmsle(y,y_pred):returnnp.sqrt(mean_squared_error(y,y_pred))3.平均するモデリング
- 4つのモデルの平均(ベースモデルEnet・KRR・Gboost,メタモデル=lasso)
- XGBoost
- LightGBM
この3つをスタッキングします!
まずは、1. 4つのモデルの平均(ベースモデルEnet・KRR・Gboost,メタモデル=lasso)から!
classStackingAveragedModels(BaseEstimator,RegressorMixin,TransformerMixin):def__init__(self,base_models,meta_model,n_folds=5):self.base_models=base_modelsself.meta_model=meta_modelself.n_folds=n_folds# モデルのクローンにデータをfitさせる
deffit(self,X,y):self.base_models_=[list()forxinself.base_models]self.meta_model_=clone(self.meta_model)kfold=KFold(n_splits=self.n_folds,shuffle=True,random_state=156)# 学習ベースモデルがフォールド外予測をします
# そのフォールド外予測はメタモデルで必要となります
out_of_fold_predictions=np.zeros((X.shape[0],len(self.base_models)))fori,modelinenumerate(self.base_models):fortrain_index,holdout_indexinkfold.split(X,y):instance=clone(model)self.base_models_[i].append(instance)instance.fit(X[train_index],y[train_index])y_pred=instance.predict(X[holdout_index])out_of_fold_predictions[holdout_index,i]=y_pred# フォールド外予測を用いてメタモデルの学習
self.meta_model_.fit(out_of_fold_predictions,y)returnself#全てのベースモデルの予測値と予測の平均値をメタ特徴として、メタモデルで最終予測を行います!
defpredict(self,X):meta_features=np.column_stack([np.column_stack([model.predict(X)formodelinbase_models]).mean(axis=1)forbase_modelsinself.base_models_])returnself.meta_model_.predict(meta_features)ベースモデルEnet・KRR・Gboost,メタモデル=lassoで適応します。
stacked_averaged_models=StackingAveragedModels(base_models=(ENet,GBoost,KRR),meta_model=lasso)score=rmsle_cv(stacked_averaged_models)print("Stacking Averaged models score: {:.4f} ({:.4f})".format(score.mean(),score.std()))Stacking Averaged models score: 0.1085 (0.0074)
平均したモデルをrmsle()で評価します!
stacked_averaged_models.fit(train.values,y_train)stacked_train_pred=stacked_averaged_models.predict(train.values)stacked_pred=np.expm1(stacked_averaged_models.predict(test.values))print(rmsle(y_train,stacked_train_pred))0.0781571937916
4. 平均しないモデリング
平均しないXGBoostとLightGBMのモデルで学習・テスト・評価します!
XGBoost
#学習
model_xgb.fit(train,y_train)xgb_train_pred=model_xgb.predict(train)#テスト
xgb_pred=np.expm1(model_xgb.predict(test))#評価
print(rmsle(y_train,xgb_train_pred))0.0785165142425
LightGBM
model_lgb.fit(train,y_train)lgb_train_pred=model_lgb.predict(train)lgb_pred=np.expm1(model_lgb.predict(test.values))print(rmsle(y_train,lgb_train_pred))0.0716757468834
5. 平均モデルとXGBoostとLightGBMをスタッキング
'''RMSE on the entire Train data when averaging'''print('RMSLE score on train data:')print(rmsle(y_train,stacked_train_pred*0.70+xgb_train_pred*0.15+lgb_train_pred*0.15))RMSLE score on train data:
0.0752190464543
アンサンブル学習
ensemble=stacked_pred*0.70+xgb_pred*0.15+lgb_pred*0.156. Kaggleの提出
sub=pd.DataFrame()sub['Id']=test_IDsub['SalePrice']=ensemblesub.to_csv('submission.csv',index=False)最後に
今回参考にしたStacked Regressions : Top 4% on LeaderBoardでは、説得力を増すための補足的なコーディングが多かったので、本記事ではかなりシンプルに書きました!
ただし、人のコードを参考にしただけなので、自分でもまだ消化し切れていない部分があります、、
例えば、
- 各モデルの利用根拠
- 最後にスタッキングする際に、重みを「0.7,0.15,0.15」にした理由
などがよくわかっていませんので、もしもわかる方がいらっしゃいましたらコメントで教えていただきたいです😣
おかしな記述があるかもしれませんが、少しでもモデリングについて参考になれば幸いです!!


















