↧
Qiitaで他の人の記事をmarkdown記法で見る方法


↧
【Windows 10】Spring Boot2 で 定期実行する方法
概要
Spring Bootで定期実行をする方法。
基本的に Spring Bootでtaskを定期実行する方法 - Qiitaの通りにやればできる。
後発のバージョンでもできたという記録。
検証環境
- Windows10
- Java : 1.8.0_221
- Spring Boot : 2.1.8
設定方法
Mainクラス
@EnableSchedulingを付与する。
RestApplication.java
packagecom.aky.restapp;importorg.springframework.boot.SpringApplication;importorg.springframework.boot.autoconfigure.SpringBootApplication;importorg.springframework.boot.builder.SpringApplicationBuilder;importorg.springframework.boot.web.servlet.support.SpringBootServletInitializer;importorg.springframework.scheduling.annotation.EnableScheduling;@SpringBootApplication@EnableSchedulingpublicclassRestApplicationextendsSpringBootServletInitializer{publicstaticvoidmain(String[]args){SpringApplication.run(RestApplication.class,args);}@OverrideprotectedSpringApplicationBuilderconfigure(SpringApplicationBuilderbuilder){returnbuilder.sources(RestApplication.class);}}Controller
定期実行したいメソッドに、@Scheduledを付与し起動タイミングを指定する。
ScheduledController.java
packagecom.aky.restapp.controller;importorg.slf4j.Logger;importorg.slf4j.LoggerFactory;importorg.springframework.scheduling.annotation.Scheduled;importorg.springframework.web.bind.annotation.GetMapping;importorg.springframework.web.bind.annotation.RestController;@RestControllerpublicclassScheduledController{Loggerlogger=LoggerFactory.getLogger("");@GetMapping("/hoge")//毎秒.//cron記法で動作@Scheduled(cron="* * * * * *",zone="Asia/Tokyo")publicvoidprintHoge(){logger.info("----------- hoge start. -----------");logger.info("5 seconds delay...");try{Thread.sleep(5000);}catch(InterruptedExceptione){thrownewRuntimeException(e);}logger.info("----------- hoge end. -----------");}@GetMapping("/fuga")//printFuga()実行完了後3秒@Scheduled(fixedDelay=3000)publicvoidprintFuga(){logger.info("----------- fuga start. -----------");logger.info("5 seconds delay...");try{Thread.sleep(5000);}catch(InterruptedExceptione){thrownewRuntimeException(e);}logger.info("----------- fuga end. -----------");}@GetMapping("/piyo")//printPiyo()実行開始後5秒@Scheduled(fixedRate=5000)publicvoidprintPiyo(){logger.info("----------- piyo start. -----------");logger.info("3 seconds delay...");try{Thread.sleep(3000);}catch(InterruptedExceptione){thrownewRuntimeException(e);}logger.info("----------- piyo end. -----------");}}実行結果
実行すると以下のようなログになる。
2020-03-15 10:45:05.042 INFO 13684 --- [ scheduling-1] : ----------- fuga start. -----------
2020-03-15 10:45:05.042 INFO 13684 --- [ scheduling-1] : fuga 5 seconds delay...
2020-03-15 10:45:10.047 INFO 13684 --- [ scheduling-1] : ----------- fuga end. -----------
2020-03-15 10:45:10.047 INFO 13684 --- [ scheduling-1] : ----------- hoge start. -----------
2020-03-15 10:45:10.047 INFO 13684 --- [ scheduling-1] : hoge 5 seconds delay...
2020-03-15 10:45:15.061 INFO 13684 --- [ scheduling-1] : ----------- hoge end. -----------
2020-03-15 10:45:15.061 INFO 13684 --- [ scheduling-1] : ----------- piyo start. -----------
2020-03-15 10:45:15.061 INFO 13684 --- [ scheduling-1] : piyo 3 seconds delay...
2020-03-15 10:45:18.061 INFO 13684 --- [ scheduling-1] : ----------- piyo end. -----------
2020-03-15 10:45:18.061 INFO 13684 --- [ scheduling-1] : ----------- piyo start. -----------
2020-03-15 10:45:18.061 INFO 13684 --- [ scheduling-1] : piyo 3 seconds delay...
2020-03-15 10:45:21.073 INFO 13684 --- [ scheduling-1] : ----------- piyo end. -----------
2020-03-15 10:45:21.073 INFO 13684 --- [ scheduling-1] : ----------- fuga start. -----------
2020-03-15 10:45:21.073 INFO 13684 --- [ scheduling-1] : fuga 5 seconds delay...
2020-03-15 10:45:26.083 INFO 13684 --- [ scheduling-1] : ----------- fuga end. -----------
2020-03-15 10:45:26.083 INFO 13684 --- [ scheduling-1] : ----------- hoge start. -----------
2020-03-15 10:45:26.083 INFO 13684 --- [ scheduling-1] : hoge 5 seconds delay...
2020-03-15 10:45:31.096 INFO 13684 --- [ scheduling-1] : ----------- hoge end. -----------
2020-03-15 10:45:31.096 INFO 13684 --- [ scheduling-1] : ----------- piyo start. -----------
2020-03-15 10:45:31.096 INFO 13684 --- [ scheduling-1] : piyo 3 seconds delay...
2020-03-15 10:45:34.098 INFO 13684 --- [ scheduling-1] : ----------- piyo end. -----------
2020-03-15 10:45:34.098 INFO 13684 --- [ scheduling-1] : ----------- piyo start. -----------
2020-03-15 10:45:34.098 INFO 13684 --- [ scheduling-1] : piyo 3 seconds delay...
2020-03-15 10:45:37.103 INFO 13684 --- [ scheduling-1] : ----------- piyo end. -----------
2020-03-15 10:45:37.103 INFO 13684 --- [ scheduling-1] : ----------- piyo start. -----------
2020-03-15 10:45:37.103 INFO 13684 --- [ scheduling-1] : piyo 3 seconds delay...
2020-03-15 10:45:40.106 INFO 13684 --- [ scheduling-1] : ----------- piyo end. -----------
2020-03-15 10:45:40.106 INFO 13684 --- [ scheduling-1] : ----------- fuga start. -----------
2020-03-15 10:45:40.106 INFO 13684 --- [ scheduling-1] : fuga 5 seconds delay...
解説
@Scheduledの使用した設定についてざっくり説明。
@Scheduled(cron = "* * * * * *", zone = "Asia/Tokyo")
cronのような記法で書くことができる。
今回の設定は毎秒実行。
@Scheduled(fixedDelay = 3000)
メソッド処理終了後、指定したミリ秒待ち実行。
今回は3秒待機。
@Scheduled(fixedRate = 5000)
メソッド実行開始から、指定したミリ秒後に実行。
今回は5秒後に実行。
詳細は、参考の公式リファレンスを参照。
参考
↧
↧
Pythonで毎日AtCoder #6
はじめに
前回
6日目です。昨日のコンテストのCに惨敗したtax_freeです。
#6
考えたこと
Aピザ、Bピザ、ABピザの組合せの最小値を求める問題です。for文でABの枚数を指定して最小値を更新していく手法で解きました。
a,b,c,x,y=map(int,input().split())price=a*x+b*yforiinrange(max(x,y)+1):price=min(price,c*2*i+max(a*(x-i),0)+max(b*(y-i),0))print(price)ABピザを0枚買ったときの値段を初期値にして、forで回しています。pythonのforはstop値-1で止まるので、+1するのを忘れるとサンプルケース3のように全部ABを買う場合が通りません。
c*2*i+max(a*(x-i),0)+max(b*(y-i),0))x < i or y < iのときに、a * (x - i)、b * (y - i)が負になることを防ぐためにmax(0,計算結果)を取って負にならないようにしています。
まとめ
このくらいのCはできるようになったのかな。本番のコンテストでもこれくらい解けるようになりたい
では、また
↧
VSCodeのコードスニペットが便利だった
概要
前回、C++の環境を構築したが、構文が覚えられず、競技プログラミングをやるときには毎回テンプレートをコピペしていた。
調べたらVSCodeにはコードスニペットを登録する機能があったので、今回はこれを使ってテンプレートを登録する。
手順
- 「ファイル」→「基本設定」→「ユーザースニペット」を選択。
言語を選ぶ。
言語毎に設定ファイルが作成される。
例:C++ → cpp.jsonファイルが開いたら以下を追記して保存する。
cpp.json
"Print to console":{"prefix":"main","body":["#include <bits/stdc++.h>","using namespace std;","","int main() {"," int n,m;"," cin >> n >> m;"," "," int r = 0;"," cout << r << endl;","}",],"description":"Main Template"}- 設定ができていると「.cpp」のファイル編集中に「main」 と打つと上のスニペットを呼び出せるようになる。
参考
↧
初心者から始めるJava、インスタンス
はじめに
この記事は備忘録である。
参考書レベルの内容だが、本記事に掲載するコードについては、間違えたものが中心となる。これは実際にコーディング中に間違えた部分を掲載し、自分で反省するために投稿するという目的によるもの。
また、後日にJavaSilver試験問題の勉強を兼ねて復習するため、深い部分の話はここでは触れない。
環境
言語:Java11、JDK13.0.2
動作環境:Windows10
インスタンス
以前、オブジェクトとインスタンスを混同して話していたように記憶しているが、改めて触れてみたい。
まずはいつもの通りCatクラスを用意する。
Cat.java
classCat{publicstaticintsumCats=0;privateintage;privatedoubleweight;publicCat(){age=0;weight=0.0;sumCats++;System.out.println("新しい猫ちゃんがやってきましたよ!");}publicvoidsetCat(inta,doublew){age=a;weight=w;System.out.println("この猫、年齢は"+age+"歳、体重は"+weight+"kgです。");}publicstaticvoidshowSumCats(){System.out.println("今は全部で"+sumCats+"匹の猫がいます。");}}このCatクラスを使って2匹の猫を用意した場合を考える。
・2匹の猫は、同じCatクラス由来である別々のオブジェクトである。
・2匹の猫は、それぞれのage,weightフィールドを有している。
以上のとき、2匹の猫はそれぞれのオブジェクトに関連付けられたフィールドであるインスタンス変数(instance variable)と、オブジェクトに関連付けられたメソッドであるインスタンスメソッド(instance method)を有する。
これらインスタンスな変数とメソッドは「オブジェクトが生成(new)されてからアクセス可能になる」。
今まで持っていた誤解
・オブジェクト≒インスタンス
⇒オブジェクト毎のフィールド・メソッド = インスタンス変数・メソッド new!!
クラス変数・クラスメソッド
しかし、オブジェクトが生成されるより前に扱いたいメンバ(フィールド・メソッド)もある。そのために、クラスそのものと関連付けがなされたメンバをstaticで宣言して使うことが出来る。
public static void showSumCats()は、public static int sumCats = 0;と宣言されたクラス変数sumCatsを参照し、newするたびにコンストラクタCat()が呼び出され、自動でインクリメントされるようになっている。これにより、「何回Catオブジェクトを生成したか」と「猫の総数」をリンクさせている。showSumCats()は、staticであるため、「一度もCatオブジェクトを生成していな」くても呼び出すことが出来るメソッドである。よって「猫0匹」を示すこともできる。
this.ってなんだろう
インスタンスメソッド内でのみ、this.ageやthis.weightと書いて、オブジェクトに関連付けられたフィールド値のみを示すように書くことが出来る。
ローカル変数の話は割愛。
終わりに
これからmain関数内で扱おうとしている変数・メソッドがクラス関連かオブジェクト関連か、staticで判別してよく理解していないと、ここを突かれる問題はかなり多い。
参考
出来るだけ自分で変数や式を書いてコンパイルしているので、完全に引用する場合はその旨記述する。
↧
↧
Windows10のDockerでCentOSの遊べる環境を作る
概要
WindowsでDockerを使う。
CentOS7イメージを作成し、インストールやコマンドの練習に使えるようにする。
適宜追記していく。
検証環境
- Windows10 Home
- Docker : 19.03.1
Docker系操作
CentOS7のイメージを取得
docker pull centos:7
起動
docker run -it -d --name centos7 centos:7
コンテナ内コマンドの実行
docker exec -it centos7 /bin/bash
- ユーザ指定で起動
docker exec -it --user <ユーザ名> centos7 /bin/bash
イメージの確認
docker images
イメージの削除
docker rmi <イメージID>
コンテナの確認
- 起動中コンテナのみ
docker ps
- 起動中コンテナ以外も
docker ps -a
コンテナの削除
docker rm <コンテナID>
- 複数削除
docker rm <コンテナID1> <コンテナID2>
- コンテナ一括削除
docker rm `docker ps -a -q`
Linux系操作
ユーザの確認
cat /etc/passwd
ユーザ追加
useradd -m <ユーザ名>
ユーザパスワード設定
passwd <ユーザ名>
参考
↧
スクロールフェードインをjQuery無しで
はじめに
jQuery使わず、フェードイン実装。いつでも見れるようにメモ的な感じでQiitaに残してます。
main.js
window.onscroll=function(){functionfadeIn(el,duration){varnode=document.getElementById(el);// display: noneでないときは何もしないif(getComputedStyle(node).display!=='none'){return;}else{node.style.display='block';}//opacityの操作node.style.opacity=0;varstart=performance.now();requestAnimationFrame(functiontick(timestamp){// イージング計算式(linear)vareasing=(timestamp-start)/duration;// opacityが1までの値を代入node.style.opacity=Math.min(easing,1);// opacityが1より小さいときif(easing<1){requestAnimationFrame(tick);}});}//ページトップ以外の時は関数を呼び出す(ページトップ時以外の時はボタンは表示される)varscrollTop=window.pageYOffset;if(scrollTop>0){fadeIn('js-button',100);}}index.html
<divid="fadein">フェードインさせる要素</div>解説
スクロールするごとに自作したfadeIn関数を呼び出す処理。
fadeIn関数が呼ばれているとき、requestAnimationFrame関数は取得したDOM要素のopacityの値を検知する役割にを果たす。
そのとき、opacityが1より小さい値が取得される間はrequestAnimationFrame関数は呼び出され続け、1以上の値になったら、呼び出しを停止させる。
perfomance.now()
Date.now()にするとうまく動かなくなる。
多分perfomance.now()は常に一定の割合で増加して、Date.now()は増加しなくて計算が続かないから?
おわりに
フェードアウトも書きます
↧
SIerに新卒で入社し一年間で、特にやってよかったこと
まえがき
SIerに新卒として入社し、一年が経ちそうです。
ここで、一年間のうちで勉強してきた中で、やってよかったことを振り返りながら紹介します。
今後IT業界に、未経験や新卒で来られる方の参考になればと思います。
- 技術面
- マインド面・その他
上記の構成で、解説していきます。
自己紹介
軽く自己紹介しておきます。
学生時代は、理系ですがあまりプログラミングはしなかったです。
プログラミング経験は、Cのみです。
現在は、とある案件でSpringを用いて開発しております。
注意事項
あくまでSIerに入社した新卒一年目が、学習した中で
特に勉強した時のリターンや、実務に有効であったものを紹介していきます。
意識の高い人は、業務に関係のないモダンな技術の学習にも取り組んでみてください。
技術面
Git
必須の技術です。
バージョン管理を行う際に、用いGitとSVNの二択となるでしょうが
Gitを選択していただくとよいかと思います。
Gitを学習した上で、GitHubや、Bitbucketなどの
Gitホスティングサービスを利用し、学習していくのがよいです。
JavaScript
私の業務上、モックの作成や製造を行ったのですが、常にJavaScriptは登場します。
そこで勉強をしようと思ったのですが非常に難しく、学習コストは高いですし、
どこから勉強すればいいのかが最初はつかみにくかったです。
本で学ぶと、情報が古かったりなどもあるためJavaScriptに関しては、適切なサイトでの学習をオススメします。
以下のチュートリアルサイトがわかりやすいため、ここで学習することをオススメします。
JavaScript Primer
ボリュームも程よく、読みやすい。
またECMAScript 2015以降をベースにしているためモダンなJavaScriptを学習できます。
現代の JavaScript チュートリアル
ボリュームが初学者にはかなり多い。
深い内容まで解説されているため、サイト内検索で解決することが多い。
学習手順
初め、私は後者のサイトで勉強をしていたのですがボリュームも多いため、最初から学習するには厳しかったです。
ですので、まずは、前者で勉強しつつ、補強したい部分や足りない部分を後者で補うという使い方がよいです。
Linux
導入作業でLinuxを触るので私の部署では、必須の技術でした。
私は、入社するまでLinuxを触ったことがありませんでしたが、IT業界に来られる方は、触っておいたほうがいいです。
学習手順
- 自宅にCentOSの導入から。会社でサーバを借りれるならそれでも良い。
- Docker Engineを導入し、何らかのコンテナをデプロイする。
- (オプション) 本は、新しいLinuxの教科書がオススメです。Redhat系、Debian系に対応しており良本です。
上記の学習だけでLinuxだけでなく、Dockerの基本まで押えることができます。
Linuxはひたすら触ってコマンドを打ちまくるのがよいです。
正規表現
資料作成や、何百、何全件ある似たようなデータをひたすら確認、修正するつまらない作業はよく発生します。
それは正規表現を使うことでカバーできます。
手作業だと、バグやミスの元で時間も無駄にかかるので、使えるようになることをオススメします。
なんとなくのイメージですが、若手は正規表現に弱い人が多い気がします。
正規表現は、同じような作業を繰り返す際に、必須ですので使えると今後が楽に、楽しくなります!
学習手順
Qiitaの以下の記事が非常に参考になります。私の正規表現はここから始まりました。
初心者歓迎!手と目で覚える正規表現入門・その1「さまざまな形式の電話番号を検索しよう」
初心者歓迎!手と目で覚える正規表現入門・その2「微妙な違いを許容しつつ置換しよう」
初心者歓迎!手と目で覚える正規表現入門・その3「空白文字を自由自在に操ろう」
初心者歓迎!手と目で覚える正規表現入門・その4(最終回)「中級者テクニックをマスターしよう」
上記での学習が完了したら、業務内の事務作業やらでアウトプットするとよいです。
マインド面・その他
優秀な先輩を目標にする
配属されてから同期にライバル視をされてきたのですが、
正直なところ同期をライバル視しているようではレベルは低いです。
優秀な先輩を見つけ、その人がやっててすごいな、良いなと思ったところは全て真似て吸収しました。
また、あまりにもすごすぎる先輩に師匠になって色々教えを乞うのもよいです。
ここで大事だと思うことですが、いきなり未知数の新人に「師匠になって」的なことを言われても「う~ん」となります。
ですので、自分の力や自走力を見せつけるのが大事です。こいつは育てる価値があるなと思われるような努力をしましょう。
事務作業をめんどくさがらない
新人ということで、飲み会の幹事や、議事録作成や電話応対など色々あると思います。
初めは、私もめんどくさいなと思ったこともあるのですが、
逆にずっと製造やテストなどのプロジェクトに携わっているのも疲れるものです。
なので、これら事務作業は「気晴らしにやるか~!」と前向きにすると、
気分も楽ですし、周りのメンバーからの目もよくなります。結構ここが重要だと思います。
幹事は、Tポイントが貯まるのでやるの大好きです。
外部セミナーに参加する
人事主催の研修やセミナーは置いておいて外部セミナーに参加してください!
興味のある業務に関係のないセミナーでもよいと思います。
自分にない知識の補填や、モチベーション向上のためにもなりますし、何より気分転換になります。
セミナーは、TECH PLAYやその他、イベント紹介サイトで探すとよいです。
もっと効率よくできないかを追求する
仕事をしているとものすごく効率の悪い作業が頻繁にあります。
その作業を実際に体験し、嫌気が刺したならそのタイミングで、他の方法を模索してみましょう。
なぜそのタイミングなのかというと、人は慣れてしまうので最初は嫌気が刺していても
我慢できるようになってしまうからです。なので嫌気が刺した瞬間がチャンスです。
ここで大切なのは以下の2点を抑えることです。
現在の作業の流れになっている背景
効率化を追求する上で、他の問題点はないか。あったとしたらそれは許容できるものか
上司と相談しつつ、プロジェクト以外の業務効率化施策などに取り組むのも技術力向上や、気分転換になり楽しいです。
嫌な業務がきたときはマインドチェンジする
私は、テストが嫌いなんですが、仕事なので嫌嫌とも言ってられません。
なのでこういう時は、考え方を変えます。
この業務をやることで自分は何を得ることができるのか?
こう考え方を変えて取り組むだけで嫌々やるよりも色々な面でよい結果になると思います。
もし、どうしても嫌な業務が来たなら先輩や上司に、該当業務の目的でも聞いてみるといいかもしれません。
Qiitaや本を読む
何の記事、本とは言いませんが、まずは興味のあるものでよいと思います。
私は、毎日Qiitaのトレンドやマイルストーンにあがる記事を空き時間に見ています。
ここで興味を持った分野の本を買って、勉強するのもいいかもしれません。
最後に
頭の中をほじくりだせば、まだまだありそうですがとりあえずこんなもんにしておきます。
技術面も大事ですが、それ以外の仕事の取り組み方のほうが重要だと思います。
結局は人と関わるお仕事ですから・・・(私は、技術よりの人間ですが)
皆様から、ご意見や感想などいただければ幸いです。
以上、ありがとうございました。
↧
C - *argv[] **argvとはなんぞや?
事の発端
今回はCS50 week2の課題 substitutionを解いているときに発見したことをシェアします。
課題の内容は以下の通り。コマンドライン引数で与えられたkeyに応じて文章を暗号化するアルゴリズムです。
1. ユーザーからkeyをコマンドライン引数として受け取る。
2. keyがアルファベット26文字を全て1文字ずつ含むように、keyの長さとアルファベット以外を含むかどうかをチェックする。
(例)有効なkey -> NQXPOMAFTRHLZGECYJIUWSKDVB(大文字小文字どちらでもよい)
3. ユーザーに暗号化したい文章を入力させる。
4. 入力された文章のアルファベットを一文字ずつそれぞれ、keyに対応させて暗号化する。
(例)A or a -> N or n, B or b -> Q or n, C c -> X or x, ...
https://cs50.harvard.edu/college/2020/spring/psets/2/substitution/
実装
まずはkeyの長さとアルファベット以外を含むかどうかを調べるところから。
必然的にユーザーによって入力された文字列が必要になります。
どうやらコマンドライン引数はmain関数に渡され、argvという配列に引数が入っているらしいので、なんとなく
char key = argv[1]
とやってみるとエラー。
argv[1]はポインタらしく、char型に代入はできないとのこと。
よくよく調べてみると *argv[] あるいは **argvというふうに、配列へのポインタもしくはダブルポインタとしてmain関数に渡されている。
main関数に渡されたコマンドライン引数は「文字列として」argvという「文字列の配列」に保存されるようです。
C言語における文字列
どうやらargvは「文字列の配列」らしい。
配列というのは、メモリ上に連続して保存された複数の値のまとまりのことです。
つまりargv 文字列の配列というのは、シンプルに文字列がたくさん集まったものという意味になります。
ここで、C言語において文字列とは「文字の配列」のことでした。
先ほどと同じように文字列というのは、文字がたくさん集まったものに過ぎないわけですね。
以上の2つを組み合わせて考えてみますと、
argvは文字列の配列である。
そして文字列は文字の配列である。
よってargvは文字の配列の配列である。
つまりargvは「文字をたくさん集めたものをさらにたくさん集めたもの」だということが分かりました。
これがわかれば、なぜargvがダブルポインタなのかもはっきりします。
**argvの正体
配列というのは、配列の最初の要素のアドレスでやりとりするものでした。
なぜなら配列を定義した時点で、配列の中に入っている要素は連続して入っているということが保証されているので、先頭要素のアドレスさえわかればいいからです。
分かりやすいように以下のように考えましょう。
char **argv = {"arg0", "arg1", "arg2"}
argvの最初の要素(arg0)にはプログラムの名前が文字列として入っています。
例えばプログラムの名前がa.outであれば、
arg0 [] = "./a.out";
となっているわけです。
2つ目の要素(arg1)には入力したコマンドライン引数の1つ目が文字列として入っています。
3つ目の要素(arg2)には入力したコマンドライン引数の2つ目が文字列として入っています。
argvは配列ですから、変数argvにはargvの配列の中の一番最初の要素(文字列)のアドレスが入っています。
つまりarg0のアドレス(&arg0)ですね。
ところがarg0もまた文字の配列つまり文字列です。
したがって変数arg0にもまたarg0の配列の中の一番最初の要素(文字)のアドレスが入っています。
つまり
arg0[0] == '.'
のアドレス(&arg0[0])ですね。
したがってargvというのはアドレスのアドレスを示す変数であるということが分かります。
アドレスを保存するための変数をポインタというのなら、アドレスのアドレスを保存する変数はポインタのポインタとなるわけです。
以上のことから、変数argvは文字列の配列つまり文字のアドレスのアドレスを保存する変数なので、定義するときはアスタリスクを2つつける必要があることが分かります。
ということでコマンドライン引数をmain関数で受け取るときは、
int main(int argc, char **argv) もしくは int main(int argc, char *argv[])
と書くことになるわけです。
こういうところがC言語は難しいと言われる所以なのかもしれませんね。
↧
↧
並列"Hello World"から始めるCUDA入門
はじめに
CUDAって、OpenMPなんかに比べると「とりあえず並列に動くコード」を書くのが難しい気がします。
私も何年か前に初めてCUDAを勉強したとき、ブロックとかスレッドとかストリームとかメモリのコピーとか、コード書く前に覚えること多すぎる...と苦しみました。コードが動くとこまでいかないと、モチベーション維持が大変ですよね。
そこで、とりあえず並列で動くHello Worldの書き方を紹介したいと思います!参考になれば幸いです。
並列処理させるための関数を作る
今回は"Hello World"を出力する関数を作り、それをCUDAで並列処理させるために書き換えていきます!
まず、C言語でベースとなるコードを書いていきましょう。
#include <stdio.h>
voidhello(){printf("Hello World !!\n");}intmain(){hello();return0;}出来ました。hello関数を呼び出すと"Hello World !!\n"が表示されます。
このhello関数を並列処理させるには、関数の先頭に__global__を付けるだけでOKです!
#include <stdio.h>
__global__voidhello(){printf("Hello World !!\n");}intmain(){hello();return0;}これでhello関数はGPUで並列処理される関数に生まれ変わりました。このように先頭に__global__をつけた関数をカーネル関数と呼びます。関数の書き換えはこれだけです。
じゃあ早速コンパイル&実行してみましょう!
: error: a __global__ function call must be configured
なんかエラーが出ましたね。まあ当たり前ですね、並列数書いてないんですから。
並列数を記述する
並列数は関数を呼び出すときに付け加えてやればOKです!
#include <stdio.h>
__global__voidhello(){printf("Hello CUDA World !!\n");}intmain(){hello<<<2,4>>>();return0;}ここで見慣れない記法が現れました。<<< 2, 4 >>>って何...?
これは、関数を呼び出す際に使用するブロック数とスレッド数を表しています。書き方は、<<< [ブロック数], [スレッド数] >>>です。CUDAではスレッドの上位階層にブロックが用意されていて、「何ブロック目の何番スレッド」と住所のように管理されています。このあたりの話は少しややこしくなるので詳しい説明はまた別途行うこととします。
この記事では、[ブロック数]×[スレッド数]だけ関数が並列処理される!とだけ覚えてください。
ブロック数とスレッド数を追記したコードでコンパイル&実行してみます。
...何も表示されません。なぜでしょうか?
カーネル関数の同期処理
実は、カーネル関数は関数内の処理の終了を待たずにCPU側(関数の外)の処理が進んでしまうんです!今回の場合だとカーネル関数呼び出し後すぐにプログラムが終了するため、Hello Worldが出力される前にプロセスが終了してしまいました。
この問題は、カーネル関数を呼び出した後にcudaDeviceSynchronize();を記述してやれば解決します。この関数の呼び出しは、カーネル関数でGPUに渡した処理が全部終わるまでCPUは待っててくださいね。という意味になります。これを反映したコードが以下です。
#include <stdio.h>
__global__voidhello(){printf("Hello CUDA World !!\n");}intmain(){hello<<<2,4>>>();cudaDeviceSynchronize();return0;}実行
今度こそ完成です。コンパイル&実行してみましょう。
Hello CUDA World !!
Hello CUDA World !!
Hello CUDA World !!
Hello CUDA World !!
Hello CUDA World !!
Hello CUDA World !!
Hello CUDA World !!
Hello CUDA World !!
ちゃんと2×4=8並列されてますね。紆余曲折ありましたが意外とすんなり並列処理できたのではないでしょうか。
まとめ
今回はできるだけ難しいことは置いといて、とりあえず並列に動くコードを書くことに焦点を当てて解説してみました。さすがにこの知識だけだと実際にCUDAを活用するには不十分化かと思いますが、少しでも勉強のお手伝いができたなら幸いです。
↧
ギョギョ!すギョい!さかなクン語話せるんすか(笑)
日本語のための自然言語処理・音声処理APIプラットフォーム COTOHA APIキャンペーンやってたんで、COTOHA APIでさかなクン語に変換するお楽しみサイトを作ってみました!ちなみに、最近のCOTOHA API記事一覧、キャンペーンの影響で、関連記事数増えてますね。

さかなクン語とは
ハコブク帽子をかぶって国会にも登場したお魚博士さかなクン。ここまで成立したキャラは今までみたことがありません。魚への熱い情熱、深い知識、歩みを止めない行動力、エンジニアとして学ばさせていただく点が多いにある方だと思います。
ここでは、お魚博士さかなクンが使う言葉を「さかなクン語」と呼ぶことにします。会話や文書の中で「ギョギョ」と魚の「ぎょ」「ギョ」を匠に使うのが特徴です。さかなクン語にはいくつかパターンがあるようです。
- 基本的に丁寧語を使う
- 「ご」を「ギョ」に変える。ただし地名や名称の場合は変えない。
- 「一期一会(いちごいちえ)」など読みに「ご」が入っている漢字は、「魚」(ギョ)に変える。
- テンションや驚いた時に「ギョギョ!」といいがち
このパターンから単に正規表現で「ご」を「ギョ」に変えるだけでは実現できないということがわかります。そのため、COTOHA APIで固有表現抽出、構文解析と感情分析を使用して次の処理をすることにしました。
- 固有表現抽出で、「ORG:組織名」「PSN:人名」「LOC:場所」「ART:固有物名」を除きます。
- 構文解析で「ご」を「ぎょ」に、読みに「ご」が入っている漢字は、「魚」(ギョ)に変えます。
- 感情分析から「驚く」「興奮」と判定された文のはじめに「ギョギョ!」を追加します。
COTOHA APIの使い方(PHP)
COTOHA APIを使用する流れ
for Developers 無料登録から登録します。
登録してログインすると、「Access Token Publish URL」「API Base URL」や認証情報の「Client ID」「Client secret」がわかります。アクセストークンを取得するため、認証情報の「Client ID」「Client secret」を「Access Token Publish URL」へ送信します。
取得したアクセストークン利用して、各APIを呼び出します。

アクセストークンを取得する
アクセストークンの有効期間は24時間なので、1日置きにアクセストークンを取得する必要があります。
アクセストークン取得(PHP)
$url=[AccessTokenPublishURL];//自分のに書き換えてください$header=['Content-Type:application/json'];$data=['grantType'=>'client_credentials','clientId'=>Client_ID,//自分のに書き換えてください'clientSecret'=>Client_secret,//自分のに書き換えてください];$ch=curl_init();curl_setopt($ch,CURLOPT_URL,$url);curl_setopt($ch,CURLOPT_HTTPHEADER,$header);curl_setopt($ch,CURLOPT_POST,TRUE);curl_setopt($ch,CURLOPT_POSTFIELDS,json_encode($data));curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);curl_setopt($ch,CURLOPT_SSL_VERIFYPEER,true);$json=curl_exec($ch);curl_close($ch);//アクセストークン$ac=$json["access_token"];固有表現抽出
固有表現抽出APIに文を送ります。オプションとして、「type」を選べます。SNSなどの崩れた文、kizunaを選んでみました。「ORG:組織名」「PSN:人名」「LOC:場所」「ART:固有物名」は、除外キーワードに入れます。
「権造さんこちらは、五所川原市でございますよ!」という文で試してみたいと思います。「権造さん」と「五所川原市」が固有表現として抽出されるのを期待します。
固定表現抽出APIを呼ぶ(PHP)
$str="権造さんこちらは、五所川原市でございますよ!";$url=[APIBaseURL]/nlp/v1/ne;//自分のに書き換えてください$header=['Content-Type:application/json;charset=UTF-8','Authorization:Bearer '.$ac//アクセストークン];$data=['sentence'=>$str,'type'=>'kuzure'];$ch=curl_init();curl_setopt($ch,CURLOPT_URL,$url);curl_setopt($ch,CURLOPT_HTTPHEADER,$header);curl_setopt($ch,CURLOPT_POST,TRUE);curl_setopt($ch,CURLOPT_POSTFIELDS,json_encode($data));curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);curl_setopt($ch,CURLOPT_SSL_VERIFYPEER,true);$json=curl_exec($ch);curl_close($ch);$NE=json_decode($json,true);$exclude_words=[];foreach($NE["result"]as$res){if($res["class"]=="LOC"||$res["class"]=="ORG"||$res["class"]=="ART"||$res["class"]=="PSN"){$exclude_words[]=$res["form"];}}おお! 「権造」は「人名」、「五所川原市」は「場所」として抽出されました! 地名や名称は、さかなくん語に変換しないので、除外キーワードに入れます。
固定表現抽出APIから返ってきた結果
array(0){}array(3){["result"]=>array(2){[0]=>array(7){["begin_pos"]=>int(0)["end_pos"]=>int(2)["form"]=>string(6)"権造"["std_form"]=>string(6)"権造"["class"]=>string(3)"PSN"["extended_class"]=>string(0)""["source"]=>string(5)"basic"}[1]=>array(7){["begin_pos"]=>int(9)["end_pos"]=>int(14)["form"]=>string(15)"五所川原市"["std_form"]=>string(15)"五所川原市"["class"]=>string(3)"LOC"["extended_class"]=>string(0)""["source"]=>string(5)"basic"}}["status"]=>int(0)["message"]=>string(0)""}構文解析
続いて、構文解析APIに文を送ります。こちらも「type」をkuzureにしてみました。除外キーワード以外、「ご」を「ぎょ」に、読みに「ご」が入っている漢字は、「魚」(ギョ)に変えます。「ご」と読む漢字をリスト化しました。
「権造さん出会いは、一期一会でございますね!」で試してみます。
構文解析APIを呼ぶ(PHP)
$str="権造さん出会いは、一期一会でございますね!";$url=[APIBaseURL]/nlp/v1/parse;//自分のに書き換えてください$header=['Content-Type:application/json;charset=UTF-8','Authorization:Bearer '.$ac];$data=['sentence'=>$str,'type'=>'kuzure'];$ch=curl_init();curl_setopt($ch,CURLOPT_URL,$url);curl_setopt($ch,CURLOPT_HTTPHEADER,$header);curl_setopt($ch,CURLOPT_POST,TRUE);curl_setopt($ch,CURLOPT_POSTFIELDS,json_encode($data));curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);curl_setopt($ch,CURLOPT_SSL_VERIFYPEER,true);$json=curl_exec($ch);curl_close($ch);$parse=json_decode($json,true);$kanjis=["互","五","伍","冱","冴","午","后","吾","呉","唔","圄","圉","娯","寤","巨","後","御","忤","悟","晤","朞","期","梧","棊","棋","檎","沍","牛","牾","珸","瑚","碁","禦","篌","糊","胡","茣","蜈","衙","語","誤","護","迓","醐","雇","麌","齬"];$sentence="";foreach($parse["result"]as$res){foreach($res["tokens"]as$token){if(strpos($token["kana"],"ゴ")!==false&&!in_array($token["form"],$exclude_words)){$token["form"]=mb_ereg_replace("ご","ギョ",$token["form"]);foreach($kanjisas$kanji){if(strpos($token["form"],$kanji)!==false){$token["form"]=mb_ereg_replace($kanji,"魚",$token["form"]);}}}$sentence.=$token["form"];}}「権造」の読みが、「ケンヅクリ」となっていますが(汗)、こういうのは、辞書の補完したらちゃんと認識してくれるものだと思うので問題ないですね(笑)「ござ」と「一期一会」を取得できたので、「ギョざ」、「一魚一会」に変えます。
構文解析APIから返ってきた結果
array(3){省略〜["tokens"]=>array(2){[0]=>array(7){["id"]=>int(0)["form"]=>string(6)"権造"["kana"]=>string(15)"ケンヅクリ"["lemma"]=>string(6)"権造"["pos"]=>string(6)"名詞"["features"]=>array(0){}["attributes"]=>array(0){}}省略〜["tokens"]=>array(7){[0]=>array(8){["id"]=>int(5)["form"]=>string(12)"一期一会"["kana"]=>string(18)"イチゴイチエ"["lemma"]=>string(12)"一期一会"["pos"]=>string(6)"名詞"["features"]=>array(0){}省略〜[2]=>array(7){["id"]=>int(7)["form"]=>string(6)"ござ"["kana"]=>string(6)"ゴザ"["lemma"]=>string(9)"御座る"["pos"]=>string(12)"動詞語幹"["features"]=>array(1){[0]=>string(2)"RX"}["attributes"]=>array(0){}}省略〜}感情分析
感情分析を「権造さん、精神が高揚していますね!」で試してみました。
感情分析APIを呼ぶ(PHP)
$str="権造さん、精神が高揚していますね!";$url=[APIBaseURL]/nlp/v1/sentiment;//自分のに書き換えてください$header=['Content-Type:application/json;charset=UTF-8','Authorization:Bearer '.$ac];$data=['sentence'=>$str,];$ch=curl_init();curl_setopt($ch,CURLOPT_URL,$url);curl_setopt($ch,CURLOPT_HTTPHEADER,$header);curl_setopt($ch,CURLOPT_POST,TRUE);curl_setopt($ch,CURLOPT_POSTFIELDS,json_encode($data));curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);curl_setopt($ch,CURLOPT_SSL_VERIFYPEER,true);$json=curl_exec($ch);curl_close($ch);$addword="";$emotion=json_decode($json,true);foreach($emotion["result"]["emotional_phrase"]as$phrase){if($phrase["emotion"]=="興奮"||$phrase["emotion"]=="驚く"){$addword="ギョギョ! ";}}$sentence=$addword.$sentence;これもいいですね!「高揚」という言葉が、「興奮」と捉えられたようです!(笑)
感情分析APIから返ってきた結果
array(3){["result"]=>array(3){["sentiment"]=>string(7)"Neutral"["score"]=>float(0.39264444089599)["emotional_phrase"]=>array(1){[0]=>array(2){["form"]=>string(6)"高揚"["emotion"]=>string(6)"興奮"}}}["status"]=>int(0)["message"]=>string(2)"OK"}感想
API叩くだけなので、手軽にすぐ使えちゃいますね。
参考
付録
あなたもさかなクン語話してみませんか😊
ギョギョ🐟 さかなクン語に変換!
ギョギョ! Thanks you! チャオ! 再見!
↧
初心者の初心者による初心者のためのニューラルネットワーク#6〜理論から実装へ:学習の工夫編〜
加筆修正のコメント等あれば、遠慮なく教えてください。
本記事は、初心者の初心者による初心者のためのニューラルネットワーク#5〜(ひと休み):分類問題における学習とは編〜の続きとなります。
1. なぜ人はニューラルネットワークを学ぶのか
今や日常生活の様々な場面に用いられている、機械学習のコアの部分だからです。(多分)
2. 本記事の目的
本記事では、ニューラルネットワークを実装する上で施されている工夫について理論的な説明を詳しくしていきます。
3. 前記事の要約
初心者の初心者による初心者のためのニューラルネットワーク〜理論:順伝播編〜では、ニューラルネットワークの基本概念、基本構造そしてアルゴリズム①である順伝播(forward-propagation)について説明しました。
その要約として以下の図をあげます。ニューラルネットワークとは、『パーセプトロン(のようなもの)を基に人間の脳神経系のニューロンを数理モデル化したもの』のことであり、『線型結合と非線形変換を繰り返す合成関数 $f(w,x)$によって入力から出力を表すモデル』です。
そして、ニューラルネットワークの目的は最適パラメータの発見であり、そのために学習を繰り返すことによって予測出力を最適化するようなパラメータを導出します。
順伝播は、その学習アルゴリズムの一つ目でした。

そして続く初心者の初心者による初心者のためのニューラルネットワーク〜理論:誤差計算編〜では、アルゴリズム②である出力値と教師信号のずれの程度を表すための誤差計算について説明しました。そして、こちらはアルゴリズム②には含まれない部分ですが、誤差関数と密接に関係する多層パーセプトロン内の活性化関数の種類とその使用場面についての説明も行いました。
以下の図は、それらの誤差関数および活性化関数の種類と、それぞれどのような問題に対し用いることが一般的なのかをまとめたものになります。
これに基づいた誤差計算は、学習アルゴリズムの二つ目でした。

そして、初心者の初心者による初心者のためのニューラルネットワーク#3〜理論:逆伝播編〜では、誤差を最小化するための学習方法として勾配降下法を適用するために、各層における誤差関数の重みに対する勾配の計算方法を導出しました。その結果、$l$層の勾配を算出するには$l+1$層の誤差信号及び$l$層への入力値を求める必要があることが分かりました。これによって、勾配降下法の多層パーセプトロン(この記事ではニューラルネットワークと同義)への適用には、あらかじめ
・ 順伝搬による各層の出力の算出
・ 出力値と教師信号の比較による誤差信号の算出
という二つのフェーズ、すなわち多層パーセプトロンアルゴリズムの①, ②をパスしなくてはいけないことが分かりました。
以下の図は、それぞれの活性化関数及び誤差関数を用いた場合の勾配の計算式を示したものです。なお、前記事の議論から、誤差信号は三つの出力関数には依らないということが分かっています。
この勾配の導出が、学習アルゴリズムの三つ目でした。
そして、学習アルゴリズムの最後である初心者の初心者による初心者のためのニューラルネットワーク#4〜理論:パラメータ更新編〜では、#3.で導出した誤差関数$E$の重み$w$に対する勾配式を勾配降下法に適用することによって、重み$w$の更新式を導出しました。そして、この逆伝播からパラメータ更新までのフローを表した手法を誤差逆伝播法(backpropagation)とし、そのアルゴリズムを示しました。そして、この誤差逆伝播法のアルゴリズムこそが、ニューラルネットワークの学習アルゴリズムになります。


引き続いての初心者の初心者による初心者のためのニューラルネットワーク#5〜(ひと休み):分類問題における学習とは編〜では、それ以前と内容が連動しているわけではなく、分類問題における学習の根幹役割について再確認しました。線形分離不可能な分類問題においては、『線形分離可能な写像先高次元空間の発見』そして『その空間内での線形分離』が学習の肝となります。これは、『$n$次元空間に$(n−1)$次元の非線形分離超平面を設けることは、$(n+a)$次元空間に$(n+a−1)$次元の線形分離超平面を設けることで補うことができる』ことによります。
4. ニューラルネットワークにおける学習の工夫
さて、それでは実装サイドの説明に入っていきましょう。と言っても、本章で説明するのはあくまでニューラルネットワークを現実問題に適用する場合に必要となる考え方であって、理論の域です。
また、入力Xはpandasのdataframe型を想定しています。
4.1. 正規化 (Normalization)
引用サイト:
ニューラルネットワークの学習の工夫
主成分分析と固有値問題
Batch Normalization:ニューラルネットワークの学習を加速させる汎用的で強力な手法
4.1.1. 正規化 (Normalization)
正規化は学習データ$\{x_1,...,x_N\}$に対して、値が0〜1の範囲に収まるように加工を施すことです。場合によっては−1〜1にすることもあります。方法は単純で、学習データの中で最も大きな値(あるいは最も大きな絶対値)を取り出し、全てのデータをその値で割るだけです。
$α = max\{x_1,...,x_N\}$
$X \leftarrow \{\frac{x_1}{α},...,\frac{x_N}{α}\}$
defnormalize(X):normalized_X=X/X.max()returnnormalized_X各次元が(身長、体重、体脂肪率)などになっていた場合は、成分毎に意味合いが全く異なるため、一般的には各成分毎に正規化をする(身長は身長だけで正規化する)ことが必要になります。
4.1.2. 標準化 (Standardization)
標準化も正規化同様取りうる値の範囲を制限するように入力データを加工をしますが、正規化ほど厳密に値の範囲を指定しません。標準化では入力データの平均を0に分散を1にするような加工を施します。これにより、データは概ね−1〜1の範囲に留まりますが、この範囲を飛び出るデータも出てきます。
$\mu = \frac{1}{N}\sum_i^{N}x_i$
$\sigma^2 = \frac{1}{N}\sum_i^{N}(x_i−μ)^{2}$
$X \leftarrow \frac{x−\mu}{\sigma}$
defstandardize(X):mean=X.mean()deviation=X-mean#偏差=データと平均の差variance=np.square(deviation).mean()#分散=偏差の二乗の平均standard_deviation=np.sqrt(variance)#標準偏差=分散の平方根standardized_X=deviation/standard_deviationreturnstandardized_XOR
importsklearnfromsklearnimportpreprocessingstandardized_X=preprocessing.scale(X)観測して集めたデータは必ずしも範囲が明確ではないため、統計的なパラメータを使ってこのような加工をするのが一般的です。なので一般に「正規化」と言ったら、この「標準化」を指すことが多いです。
4.1.3. 無相関化
無相関化は多次元データの各成分$x=(x_1,x_2,...,x_d)^T$が何らかの関係を持っている場合に、その関係性を解消することに使われます。
例えば天候に関するデータ(雲の量、気温、紫外線量)などが集まったとすれば、明らかにデータの各成分は何らかの関係性を持っています。
このような場合に、
新しい指標1=A×雲の量+B×気温
新しい指標2=C×雲の量+D×紫外線量
という計算をして、新しい指標1と新しい指標2が無相関にしてみます(そのようなABCDを見つける)。
この新しい指標は物理的に何を意味しているかは定かでないにしても、天候に関するデータから遊園地の来場者数を予測したい場合に置いて、役立つ指標が出来上がるかもしれません。
また、出来上がった指標のうち、重要な指標はごく少数かもしれません。この前処理は主成分分析と全く同等のもので、新しい指標のことを主成分と呼びます。
主成分を少数取り出せば特徴抽出として使えますが、全ての成分を残しても構いません。
この無相関化は主成分分析 (Principal Component Analysis; PCA)にも大きく関連します。詳しい説明についてはニューラルネットワークの教師なし学習:次元削減のところで行おうと思いますが、無相関化も主成分分析もその大枠のステップ自体は同じであり、それは以下からなります。
- ある方向に射影した時のデータの分散を計算する← 分散共分散行列が必要になる
- 分散が最大になるような方向を見つける← 固有値問題に落とし込めるので、固有ベクトルを求める
- その方向に写像する← 固有ベクトルは回転行列となるので、元データXとの内積を計算する
defuncorrelate(X):sigma=np.cov(X,rowvar=0)#分散共分散行列を求める _,S=np.linalg.eig(sigma)#それを元に固有値,固有ベクトルを得るdf_S=pd.DataFrame(S)#dataframe型に変換uncorrelated_X=df_S.T.dot(X.values.T).T#固有ベクトルを転置し内積をとり写像させるreturnuncorrelated_Xここで、最後に線形変換を行うとき、転置行列を写像しなければいけないようです。この理由については申し訳ないのですが分かりませんでした。どなたか知見のある方がいらっしゃれば教えて頂ければ幸いです。
4.1.4. 白色化
無相関化して出来上がった新たな指標(主成分)は、各成分毎に全く取りうる値の範囲が異なります。特徴抽出(主成分分析)が目的であれば、無相関化したデータを用いるのがベターでしょう。
しかし、あくまで無相関にしたいだけであったならば、成分毎に値の大きさが全く異なるのは不都合である場合があるので、取りうる値の範囲を制限したいということになります。
そこで無相関化して出来上がった新たなデータに対して、標準化を適応するのが白色化です。
通常、無相関化の処理を行う時点で平均は0に直され、分散は固有値問題を解いた際に得られるため、無相関化の処理の中で白色化の処理を簡単に追加することが可能です。
defwhiten(X):uncorrelated_X=uncorrelate(X)#無相関化whitened_X=standardize(uncorrelated_X)#標準化returnwhitened_X4.1.5. バッチ正規化 (Batch normalization)
さて、これまでの説明は正規化や標準化といったデータの前処理におけるものでしたが、データセットだけ正規化されていても、ネットワーク内部で分散が偏ってしまいます。
そこでバッチ正規化では、入力層だけでなく各層ごとに正規化(=標準化)を行います。
バッチ正規化には二種類あり、各層に入力が入る直前に標準化を行う場合もあれば、層が出力を行った直後に標準化を行う場合もあります。これらの違いは、線形変換と標準化の順序をどうするかというところです。
ある層の計算は、以下のように線形変換をしてバイアスを加えた後に活性化関数を作用させることで達成されます。
$$y=f(Wx+b)$$
ここでバッチ正規化の処理をBN(・)で表現するとして、
$$y=f(W(BN(x))+b)$$$$or$$$$y=f(BN(Wx+b))$$
の違いです。ラダーネットワークでは後者の方法が取られていますが、必ずしもこちらが良いとは限らないようです。
また、バッチ正規化を行うメリットとしては、
大きな学習係数が使える
学習係数を上げるとパラメータの値によって、勾配消失・爆発することが分かっていました。バッチ正規化では、伝播中パラメータの値に影響を受けなくなります。結果的に学習係数を上げることができ、学習の収束速度が向上します。正則化効果がある
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shiftによれば、- L2正則化の必要性が下がる
- Dropoutの必要性が下がる
初期値にそれほど依存しない
ニューラルネットワークの重みの初期値がそれほど性能に影響を与えなくなります。
importtflearnfromtflearn.layers.normalizationimportbatch_normalizationnetwork=batch_normalization(network)このコードをニューラルネット構成のアルゴリズムに組み込むことによって、バッチ正規化が行われます。
4.2. 正則化 (Regularization)
引用サイト:
ニューラルネットワークの学習の工夫
正則化とは、過学習を防いだり未知パラメータ数が方程式よりも多い不良設定問題を解いたりするために、パラメータに制約を課す手法のことを指します。
分類にしても回帰にしても、入出力関係$y=f(w,x)$について$w$を上手く調整するのが目的です。しかしこの際に$w$が際限なく自由に値を取れてしまっては、トレーニングデータに対して過学習してしまう危険性があります。
正則化では、$w$に対して何らかの制約を入れることによって過学習を防ぎます。
学習が損失関数$L(w)$を最小化するという形で定式化されている場合、この損失関数に加えて正則化項$λR(w)$を追加します。
一般的な形としては、
$$L(w)+λR(w)$$
という表現になり、$λ$は正則化の強さを決める度合いです。メインはあくまで第一項の方であるため、通常$λ$は0.001〜0.1などと小さな値が設定されます。
最小化をする際に、Lの方を小さくできた(学習が進んだ)としても、Rの方をあまり大きくするのはダメですよという制約を入れていることになります。
4.2.1. L1正則化 (L1 regularization)
$L1$正則化は、パラメータ$w$の成分が0となりやすいように制約を入れます。この正則化によって、学習データが膨大な次元を持っていたとしても不要な成分を落としてくれるため、過学習が抑えられることが期待できます。最小化するための損失関数は、
$$L(w)+λ|w|_1$$
$$|w|_1=w_1+w_2+...+w_n$$
という形になります。$|w|_1$は$w$の$L^1$ノルムと呼ばれ、各成分の絶対値の和を表します。したがってこの値を小さくするためには、多くの成分が0になる必要があります。
4.2.2. L2正則化 (L2 regularization)
$L2$正則化は、パラメータ$w$をベクトルと見たときに、ベクトルがあまりに大きくなることを防ぐ制約を入れます。最小化するための損失関数は、
$$L(w)+λ|w|_2$$
$$|w|_2=\sqrt{w_1^2+w_2^2+...+w_n^2}$$
という形になります。$|w|_2$は$w$の$L^2$ノルムと呼ばれ、各成分の二乗を考慮することになるため、極端に大きな成分が現れるのを防いでくれます。
4.2.3. Elastic-Net
Elastic-Netは特に特別な概念ではなく、L1正則化とL2正則化を両方入れるものです。最小化するための損失関数は、
$$L(w)+λ\{α|w_1|+(1−α)|w_2|\}$$
ここで、$λ$はいつもどおり正則化の強さを決める係数です。αはL1正則化とL2正則化をどれだけの割合で混ぜ込むかを決める係数です。細かいこと気にしなければとりあえず、両方ぶち込んで適当にそれぞれ係数決めればいいです。単純に正則化を入れまくってるものだと思えば、当然分類問題でも応用可能です。
4.3. ドロップアウト (Dropout)
ドロップアウトとは、ニューラルネットワークを学習する際に、ある更新で層の中のノードのうちのいくつかを無効にして(そもそも存在しないかのように扱って)学習を行い、次の更新では別のノードを無効にして学習を行うことを繰り返すことによって、過学習を防ぐ手法のことです。
要するに、情報の伝達をあえて断ち切り、少数の情報だけで学習を行うようにする手法です。
ある層の出力$y$に対して以下の線形変換がなされるとき、
$$y=f(Wx+b)$$ドロップアウトはこのときの$y$の成分を一定の割合で0にしてしまいます。
(画像出典:ディープラーニングを支える黒魔術「ドロップアウト」)

厳密には、ドロップアウトによる不活性化の選択は、各層に対してドロップ確率$p$が付与されるわけではなく、ドロップアウトを仕込んだ層の各ノードごとに対して掛けられます。よってユニット数は、中間層の数を揃えていたとしても、ドロップアウトを混入させることで変化します。
これによって、学習を行う度に選択されるユニットが大きく異なり、アンサンブル学習における精度向上に寄与します。
ドロップアウトによって、単体での性能がちょっと低くなりますが、互いを補い合える「弱学習器」を寄せ集めることで精度の向上を図ることがアンサンブル学習の基本的な考えです。
しかし実際にテストデータを分類させる際には、全てのユニットを用いることに注意してください。
4.4. アーリーストッピング (Early stopping)
アーリーストッピングもまた、過学習を防ぐための手法の一つです。
ただ他の手法と異なる点として、アーリーストッピングは過学習に陥る前に学習そのものを打ち切るという点が挙げられます。
アーリーストッピングは、学習データの一部を学習用(訓練データ)と評価用(検証データ)に分けます。そして、学習中に評価データを用いた精度算出およびパラメータを保存し、過学習の傾向が見え始めた時点で学習を打ち切ります。
(画像出典:見て試してわかる機械学習アルゴリズムの仕組み 機械学習図鑑)

上図では、学習回数がある閾値を超えると、訓練データでの精度は向上している一方で、検証データでの精度は低下しています。アーリーストッピングでは、これを過学習と捉え、検証データにおける精度が最も高いパラメーターを保存することで、過学習を防ぎます。
4.5. 勾配降下オプティマイザ
引用サイト:
勾配降下法の最適化アルゴリズムを概観する
今更聞けないディープラーニングの話【ユニット・層・正則化・ドロップアウト】
しかし、仮にニューラルネットの設計や、正則化が上手く働いていても、かならずしも学習結果が良くなるとは限りません。ニューラルネットは基本的に勾配法と呼ばれる方法で、損失関数を減少させる方向に少しずつ進んでいきます。しかし、学習の開始地点から、本来到達したい地点まで、損失関数が綺麗に減少していくとは限りません。
ニューラルネットは$w$を少しずつ調整しながら、学習データを表現できるように学習を進めていくのですが、進んでいく過程に、その周りよりは損失関数が小さくなる地点が存在し、そこにハマってしまうのです。
このような局所解や鞍点というのは勾配法にとっては偽物の解として振る舞います。そして、ニューラルネットには鞍点が非常に多く存在するようです。
このような問題に対処するための勾配降下法の最適化アルゴリズムとして、以下が挙げられています。
- モメンタム法
- AdaGrad
- RMSProp
- Adam
詳細については別記事で取り上げたいと思いますが、一般的にはAdamが用いられることが多いようです。
4.6. ノイズ混入
ニューラルネットを学習させる際に,わざと入力データにランダムにノイズを混入させる手法として扱われています。
5. ニューラルネットワークにだって色々あるの
ニューラルネットワークの中間層を多層にする手法として、畳み込みニューラルネットワーク (Convolutional Neural Network: CNN)や再帰型ニューラルネットワーク (Recurrent Neural Network: RNN) があります。CNNとは、畳み込み層(フィルタリングをして特徴量を取り出す層)とプーリング層(フィルタの結果から選択する層)を交互に繰り返すことでデータの特徴を抽出し、最後に全結合層で認識を行う手法です。一方RNNとは、中間層において、中間層の結果を自ら再度入力に用いることで、文脈理解を可能にする手法です。単純化すると、CNNが順次処理、RNNが再帰処理ということになるでしょうか。
6. 参照
今更聞けないディープラーニングの話【ユニット・層・正則化・ドロップアウト】
ニューラルネットワークの学習の工夫
勾配降下法の最適化アルゴリズムを概観する
↧
Amazon Linux 2のsshd_configとauthorized_keysを学ぶ
内容
初期Amazon Linux 2の/etc/ssh/sshd_config設定を色々と変更しつつsshd_configについて学んでいく。
ついでにauthorized_keysも。
ちょっとだけsshd_configを学ぶ
取り敢えず使いそうなところの設定
| 意味 | 該当箇所 |
|---|---|
| パスワード認証 | PasswordAuthentication |
| チャレンジレスポンス認証 | ChallengeResponseAuthentication |
| 公開鍵認証 | PubkeyAuthentication |
| rootログイン | PermitRootLogin |
| 接続ポート | Port XX(基本22) |
| SSH接続バージョン | Protocol |
Amazon Linux 2の初期設定
設定
#Port 22#PubkeyAuthentication yes# the setting of "PermitRootLogin without-password".# To disable tunneled clear text passwords, change to no here!#PasswordAuthentication yes#PermitEmptyPasswords noPasswordAuthenticationno# Change to no to disable s/key passwords#ChallengeResponseAuthentication yesChallengeResponseAuthenticationno#PermitRootLogin yesどういう設定が良いのか
を調べてみた所共通して多く出てきたのが以下設定。
・rootログインの禁止
・パスワード認証の禁止
・公開鍵認証の
・SSH接続Verison 2のみ許可
・チャレンジレスポンス認証を無効化
| 推奨値 | 設定値 | 推奨値との比較 |
|---|---|---|
| rootログインの禁止 | #PermitRootLogin yes | × |
| チャレンジレスポンス認証 | ChallengeResponseAuthentication no | 〇 |
| 公開鍵認証の許可 | #PubkeyAuthentication yes | 〇 |
| SSH接続Verison 2のみ許可 | 設定見つけられず | ? |
| パスワード認証の禁止 | PasswordAuthentication no | 〇 |
ここで、×と?だったものに関して接続を試してみるとどうなるのかを検証。
rootログインの禁止
/etc/ssh/sshd_configのrootログインに関する設定値は以下であった
#PermitRootLogin yes
ただし、公式サイトでは以下のように記載されている。
Amazon Linux 2
デフォルトで安全
Amazon Linux 2 では、SSH キーペアの使用およびリモートルートログインの無効化により、リモートアクセスが制限されています。また、Amazon Linux 2 では、必須ではないにもかかわらずインスタンスにインストールされるパッケージの数が削減されるため、セキュリティの脆弱性のリスクを抑えることができます。深刻度が "緊急" または "重要" であるセキュリティアップデートは、初回起動時に自動的に適用されます。
試してみないと良く分からないので試してみます。


Tera Termを使用して、ユーザーをrootとし接続してみます。
......
.......
........
.........
Please login as the user "ec2-user" rather than the user "root".
_人人人人人人_
> ナニコレ <
 ̄Y^Y^Y^Y^Y^Y^ ̄
結果、公式通りrootでのログインはできなかったが、rootログイン時に出力される上記の文は
どこに設定されているのかは知っておきたかったので色々と調べてみた所以下に設定されていることが分かりました。
/root/.ssh/authorized_keys
no-port-forwarding,no-agent-forwarding,no-X11-forwarding,command="echo 'Please login as the user \"ec2-user\" rather than the user \"root\".';echo;sleep 10" ssh-rsa <文字列> <キーペア名>
上記が何かというとauthorized_keysのオプションで、色々設定できるらしいです。初めて知りました。
今回の場合だとssh-rsaの前に記載されています。
| オプション | 意味 |
|---|---|
| no-port-forwarding | ポート転送禁止の設定 |
| no-agent-forwarding | 認証エージェント転送禁止の設定 |
| no-X11-forwarding | X11(画面)転送禁止の設定 |
| command="command" | 実行可能なコマンドの設定 |
オプション消したらrootでログインできるのでは...?
という事で、バックアップを取得してからssh-rsaより前を削除してみます。
# cp -p /root/.ssh/authorized_keys /root/.ssh/authorized_keys_yyyymmdd
# ls -a /root/.ssh/
# vi /root/.ssh/authorized_keys
# cat /root/.ssh/authorized_keys
# systemctl restart sshd.service
authorized_keysの設定が反映されたので、新しくSSH接続を試してみます。
※無いとは思いますが何かあって入れなくなると困るので現在の接続は保ったままとします。
できました。
念のためにユーザ確認をしてみます。

# whoami
root
ログインすることができました。
authorized_keysのオプションを無くした状態でsshd_configの#PermitRootLogin yesを以下のように変更するとどうなるのかを試してみます。
(変更前)
#PermitRootLogin yes
(変更後)
PermitRootLogin no
sshd_configのバックアップを作成して、バックアップがあるかを確認します。
その後設定を変更して、設定反映をします。
# cp -p sshd_config sshd_config_yyyymmdd
# ls -l
# vi /etc/ssh/sshd_config
# systemctl restart sshd.service
それでは新しい接続でrootのログインを試してみます。

認証に失敗しました。再試行してくださいと表示されてrootにログインすることができなくなりました。
なので、デフォルトでauthorized_keysのオプションによりログインが出来なくなっていて、
そのオプションを削除するとsshd_configにてPermitRootLogin noとなっていないため
rootでログインできることが分かりました。
結果
| sshd_config | authorized_keys | 接続可否 |
|---|---|---|
| #PermitRootLogin yes | オプション有 | × |
| #PermitRootLogin yes | オプション無 | 〇 |
| PermitRootLogin no | オプション有 | × |
| PermitRootLogin no | オプション無 | × |
sshd_configでPermitRootLogin noと設定した方が良いことが分かる。
SSH接続Verison 2のみ許可
Tera TermでSSHバージョン(V)を[SSH1]を選択して[OK]を押下します。


...
....
.....
_人人人人人人_
> できない <
 ̄Y^Y^Y^Y^Y^Y^ ̄
/etc/ssh/sshd_configにはProtocolの設定がなかったが何故だろうと思い調べた所
OpenSSH 7.4でSSH v1は廃止されたとのこと。つまり何もせずともSSH v2となる。
OpenSSH 7.4/7.4p1 (2016-12-19)
- This release removes server support for the SSH v.1 protocol.
Amazon Linux 2はどのバージョンなのかを確認してみる。
# ssh -V
OpenSSH_7.4p1, OpenSSL 1.0.2k-fips 26 Jan 2017
OpenSSH 7.4p1でした。
結果
OpenSSH_7.4よりSSH v1が廃止されたため、特に何もせずともSSH v2となっていた。
終わり
最後にもう一度比較してみたいと思います。
| 推奨値 | 設定値 | 推奨値との比較 |
|---|---|---|
| rootログインの禁止 | #PermitRootLogin yes | 〇 |
| チャレンジレスポンス認証 | ChallengeResponseAuthentication no | 〇 |
| 公開鍵認証の許可 | #PubkeyAuthentication yes | 〇 |
| SSH接続Verison 2のみ許可 | 設定見つけられず | 〇 |
| パスワード認証の禁止 | PasswordAuthentication no | 〇 |
初期Amazon Linux 2の設定は何も設定しなくても上記の推奨値に関しては問題ないことが分かった。
知らないことだらけだったためとても勉強になった。
↧
↧
ライブラリ作ったから見てくれ
申し訳ありません。「見て下さい。」ですね。
調子乗りました。
気を取り直して
こんにちはこんばんは。初投稿のいるべです。
昨年クリスマスに独り身でしにたくなったのでswiftの勉強を始めました。
情報系の学部にいながらプログラミングとは関わらない生活をしていたのでプログラミング歴は実質3ヶ月程となります。
今、自分のお気に入りのものを教えてよって主旨のアプリを作成してます。SNSは素人には無理ゲーとか言う声が聞こえてきそうですがまぁやるだけタダなので黙ってて下さい。
今回は表題の通り。そのアプリを作る上で欲しくなった機能をライブラリとして作成したので、「まぁ見てって下さいよ」というところでつらつらと書かせて下さい。
ただの宣伝にならないように色々と書けたらいいなと思います。
まず前提。なんでこんなものを作ったか、だ。
いやいや、その「こんなもの」を先に言えよと思う方もいらっしゃるかも知れんがスルーします。
UICollectionViewって意味分かんなくね?
玄人の皆様方に置かれましては何が?と思われるかも知れないが、
- まずdelegateが意味わからん。
- flowlayout何それ??
- そもそもRunさせても何も表示されん、、
その他壁は沢山あると言っても過言では無い。(断言)
少なからず全く調べずにcollectionViewを使って意図した挙動を実装することができる人はそう多く無いのではと考えている(え?みんなふつーに書けるの、、?)
みんな悩んでるやろし作ったろ!
まぁもちろん既に上位互換ライブラリは存在していますが経験です。沢山勉強になりました。
僕と同じような初心者の皆様方も、「既にあるからそれ使おう」「既にあるから作るのやめよう」と言うのは悪くも無いけど良くも無いことがあるということを覚えておきましょう。たまには遠回りも必要ということです。
お待たせたしました。
今回作ったものはこちらになります。
と画像をのっけてもインパクトがない。。
真ん中下のネコを妹に描いてもらった。ほんの1分程度でさらっと。すごい。

タグを簡単に生成したいやんってことでCheckableTagというライブラリを作成しました。
簡単に説明しますと、簡単にタグを作成できるライブラリです。
更に、タップしたら色が変わるようになっているのでチェックボックスのような使い方もできます。
画像を見ての通り、タグの形にもいくつかあるので選ぶのに悩んじゃいますね?(☝︎ ՞ਊ ՞)☝︎
導入
現在はPodのみの対応です。
pod 'CheckableTag'
を追加してpod installして下さい。
使い方
importUIKitimportCheckableTagclassViewController:UIViewController{letitems=["Hello"]lettagView:CheckableTag={letview=CheckableTag()returnview}()overridefuncviewDidLoad(){super.viewDidLoad()tagView.frame=self.view.boundsself.view.addSubview(tagView)tagView.dataSource=self}}extensionViewController:CheckableTagDataSource{funcgetSelected(sender:CheckableTag)->[Bool]?{returnnil}funcgetItems(sender:CheckableTag)->[String]{returnitems}}最低限のコードはこれだけです。
これで、下のような感じになります。

*トリミングしてあります。
タップすると、
色が変わります。

プロパティ
まぁここは興味があれば自由に弄ってみて下さい。
いるべ的には下記の設定が好きです。
//tagの形を変更tagView.cellType=.curve//tagの表示スタイルを変更tagView.cellStyle=.groove//ユーザが選択可能かどうか指定tagView.canSelected=false//フォントサイズの指定。fontsizeによってtagのサイズが変わる。tagView.fontSize=20色の変更
/// 選択状態の色を指定する/// - Parameters:/// - text: テキストカラー/// - back: バックグラウンドカラー/// - line: 枠線カラーtagView.setSelectedColor(text:.white,back:.red,line:.black)/// 非選択状態の色を指定する/// - Parameters:/// - text: テキストカラー/// - back: バックグラウンドカラー/// - line: 枠線カラーtagView.setUnSelectedColor(text:.gray,back:.white,line:.gray)選択状態の取得
//存在する全てのタグの選択状態を取得します。//trueのとき選択されている//falseのとき非選択状態。letisSelectedArray:[Bool]=tagView.getIsSelected()細かいことを指定する場合
DataSourceの使用例
tagView.dataSource=self------------------------------extensionViewController:CheckableTagDataSource{///初期選択状態を指定できる。///canSelect = falseにしてこれと組み合わせればタグになる。funcgetSelected(sender:CheckableTag)->[Bool]?{return[true,false,true,false,true,true]}///tagを生成するためにタグのテキストを伝えられる。funcgetItems(sender:CheckableTag)->[String]{returnitems}}Delegateの使用例
tagView.delegate=self----------------------------extensionViewController:CheckableTagDelegate{///セルを選択したときの動作を設定できる。funcdidSelected(cell:CheckableCellProtocol){print(cell.textLabel.text)}}Animationの使用例
tagView.animation=self----------------------------///このアニメーションは意味不明なのでただの参考として扱って下さい。extensionViewController:TouchCellAnimationProtocol{///タップし始めのときに行われるアニメーション。functouchStartAnimation(cell:CheckableCellProtocol){UIView.transition(with:cell,duration:1.0,options:[.transitionFlipFromTop],animations:nil,completion:nil)}///タップ終わりのときに行われるアニメーション。functouchEndAnimation(cell:CheckableCellProtocol){UIView.transition(with:cell,duration:1.0,options:[.transitionFlipFromBottom],animations:nil,completion:nil)}}選択状態について
collectionViewやtableViewの選択状態を管理する時にスクロールしたら選択状態がずれていることがあります。
これはセルごとで選択状態を管理するのではなく、セル全ての選択状態を管理する配列を用意してそれを読んであげればそんな問題とはおさらばです。
///collectionviewを使っている上位view//cellに代入するテキストの配列。private(set)varitems:[String]=[]//cellの選択状態を管理する配列publiclazyvarisSelectedItems:[Bool]={return[Bool].init(repeating:false,count:items.count)}()///cellが生成されるタイミング/// UICollectionViewDataSourceを継承publicfunccollectionView(_collectionView:UICollectionView,cellForItemAtindexPath:IndexPath)->UICollectionViewCell{//cellを再利用するために引っ張り出してくるletcell=collectionView.dequeueReusableCell(withReuseIdentifier:"Cell",for:indexPath)//選択状態を管理している配列から、今扱っているcellに該当する選択状態を見て、それに見合ったスタイルを反映する。ifisSelectedItems[index.row]{cell.selectedColor(text:textColor,back:backColor,line:lineColor)}else{cell.unSelectedColor(text:textColor,back:backColor,line:lineColor)}returncell}Enumは便利。
Enumってすごいですね。僕は気持ちが先走ってよくタイポをしてしまう人間なのですが,
予測変換で出てこればタイポもないし、後からの要素の追加も楽々!今回はEnumと後述するProtocolに救われました。
publicenumCellType:String{casesquare="SquareCheckableCell"casecurve="CurveCheckableCell"caseround="RoundCheckableCell"casecircle="CircleCheckableCell"}これは実際のコードです。Stringがうだうだしてますね。
タイポしやすい文字列もcellType.rawValue
を使えばここで設定している文字列が取得できますからタイポが一気に減ります。
最初はcase squareだけだったんですが、一度一通り作って仕舞えばもう簡単!
case *** と新しい要素をここに追加してビルドします(おい)
もちろんビルドは通りません。
そのビルドに対して出たエラーのところを修正すればあら不思議。
もうまた別の要素が使えるようになっているではないですか。
///指定されたcellのタイプを返す。publicfuncgetCellType(collection:UICollectionView,index:IndexPath)->CheckableCellProtocol{switchcellType{case.square:returncollection.dequeueReusableCell(withReuseIdentifier:cellType.rawValue,for:index)as!SquareCheckableCellcase.curve:returncollection.dequeueReusableCell(withReuseIdentifier:cellType.rawValue,for:index)as!CurveCheckableCellcase.round:returncollection.dequeueReusableCell(withReuseIdentifier:cellType.rawValue,for:index)as!RoundCheckableCellcase.circle:returncollection.dequeueReusableCell(withReuseIdentifier:cellType.rawValue,for:index)as!CircleCheckableCell}}今回はご覧の通り似てるけど違うものをいくつも作ったのでstrategyパターンを採用しました。(実は後付け)
これとenumのおかげで今後も変更がだいぶ楽になりそうです。
Protocolくんありがとう。
protocolの何が便利かというと後からの変更がとても楽です。追加も楽です。
protocolで決まりを作っておけば後はボーッとコーディングできる。
importFoundationimportUIKitpublicprotocolCheckableCellProtocol:UICollectionViewCell{///cellの細かな表示を変更するvarcellStyle:CellStyle{getset}///cellとcontentViiewの間のマージンvarmargin:CGFloat{get}///collectionviewに最初からあるviewvarcontentView:UIView{get}///textを表示するために一番中心に配置されるviewvartextLabel:UILabel{get}///アニメーションを行うためのプロトコルvaranimationProtocol:TouchCellAnimationProtocol!{getset}///labelに表示するテキストをセットするfuncsetTextToTextLabel(textName:String)///選択時の色設定funcselectedColor(texttextColor:CellColor?,backbackColor:CellColor?,linelineColor:CellColor?)///非選択時の色設定funcunSelectedColor(texttextColor:CellColor?,backbackColor:CellColor?,linelineColor:CellColor?)///cellを設定funcsetCell()///normalstyleの設定。cellにぴったりくっつくfuncsetNormalStyle()///groovestyleの設定。cellとの間に少し溝を作るfuncsetGrooveStyle()}///共通してるものはもう作っておくextensionCheckableCellProtocol{publicvarmargin:CGFloat{returnLayoutConstants.margin}publicfuncsetTextToTextLabel(textName:String){textLabel.text=textName}publicfuncselectedColor(texttextColor:CellColor?,backbackColor:CellColor?,linelineColor:CellColor?){textLabel.textColor=textColor?.selectedColor??.whitecontentView.backgroundColor=backColor?.selectedColor??.init(red:255/255,green:100/255,blue:100/255,alpha:1)self.layer.borderColor=lineColor?.selectedColor?.cgColor??UIColor.gray.cgColor}publicfuncunSelectedColor(texttextColor:CellColor?,backbackColor:CellColor?,linelineColor:CellColor?){textLabel.textColor=textColor?.unSelectedColor??.graycontentView.backgroundColor=backColor?.unSelectedColor??.init(red:230/255,green:230/255,blue:230/255,alpha:1)self.layer.borderColor=lineColor?.unSelectedColor?.cgColor??UIColor.gray.cgColor}publicfuncsetCell(){switchcellStyle{case.normal:setNormalStyle()case.groove:setGrooveStyle()}}publicfuncsetNormalStyle(){textLabel.frame=contentView.bounds}publicfuncsetGrooveStyle(){contentView.frame=CGRect(x:self.bounds.minX+margin,y:self.bounds.minY+margin,width:self.bounds.width-margin*2,height:self.bounds.height-margin*2)textLabel.frame=contentView.bounds}}
protocolのextensionを使えば、必ず同じな部分の実装を楽に共通化できるのでとても便利。まぁclassを継承しても良いんだけどprotocolは直接インスタンス化できないところが好き。
ストラテジーパターン
ストラテジーパターンを使うと同じようなものをいくつも作成する時に追加が楽。変更も楽。
やり方は、ルール(プロトコル)を作ってそのルールに則って種類の分かれる奴らをそれぞれ作る。今回で言えばCheckableCellProtocolを作ってそれに則ったcellをSquare, Curve, Round, Circleと作った。それらを利用する側は外部からそのプロトコルに則ったインスタンスを貰うかそれを特定できる情報をもらうようにすれば完成。後は簡単に追加削除変更なんでもござれ。
具体的には上記のgetCellType関数が肝になっているのでgithubから見てみてね。
さてこのライブラリの完成度は如何程か?
良かった点
- 割と使いやすいのでは?
- 変更しやすかった。楽しくコーディングできた。
- 自分の理想にかなり近い。
改善点
- はいまずUITestが通りません。意味がわかりません。調べたところdelegateが動作していないのが原因っぽいのですがだからと言ってどうすれば解決するのかさっぱりわからない。要勉強ですね。
- delegateでタグ同士の間のスペースとか指定できるようにしたい。
- github全部ニホンゴ。
- コードレイアウトマンなのでstoryboardで使えるか確認していない。。(近日中に必ず確認して使えるようにするつもりではあるが)
- CellTypeもCellStyleももっと種類増やしたい。
- タグ左寄せの設定もできるようにしたい。
自己評価は120点!良くがんばりました。これからも頑張りましょう!(文句言うな。)
初心者をはじめこの記事を読んで下さった皆様方。
軽い感じで読みやすくしようと思って書いていましたがそうでもなくなってしまいましたね。もっと色々書きたかったけど難しいし体力切れや。
飛ばし飛ばしでもここまで読んで下さってありがとうございました。解説の部分はあんまり参考にならなかったと思います。定期的にアウトプットしてしっかり言語化することが大事だと感じました。
改善点はまだまだありますがぜひ一度使ってみて下さい。そしてissueやPR投げてくださると嬉しいです。
なぜ「初心者をはじめ」と書いたかと言いますと、このコードは簡単なコードで書かれています。まぁ初心者が書いている+他人のコードなので読みにくいかも知れませんが。もっとプログラミング出来るようになりたいと考えている方は、OSSにPR投げたりしてcontributionを重ねていくことって大事だと思うのでそれのとっかかりとして、まずこのライブラリにPRを投げるのも良いと思うよってことが言いたかったです。
READMEのちょっとした修正やタイポ修正などでもこちらとしては本当に助かりますしいわゆるwin-winですね。(古い?)こんなのどうや?って気軽に投げて下さい。
※この記事の内容は変なこと言っている可能性も大いにあります。情報の取捨選択をうまく行って、僕には文句ではなく指摘をしてくださると踊って喜びます。
長文駄文失礼しました。ありがとうございました。
↧
PythonでABC158のA~Cを解く
はじめに
忘れてて参加できなかったので解く。深夜テンションで解いた + 深夜に書いてるので、文が崩壊しているかもです。
A問題
考えたこと
Sの中にあるA,Bを数えればいい。全てA,Bであるときだけ、Noにすればいい。。str.countでカウントしてifにつっこんだ。
s=str(input())station_a=s.count('A')station_b=s.count('B')ifstation_a!=3andstation_b!=3:print('Yes')else:print('No')B問題
考えかた
A+Bの組がNに何個あるかを数えればよい。$A+Bの組の数*A$だけでは、余りの個数を含んでいません。ですので$N % (A + B)$で余りを計算してそれを足します。と思ったら余りが、Aよりも大きくなる場合もあるのでmin(a,(n % (a + b)))を足してます。
n,a,b=map(int,input().split())p=n//(a+b)ans=a*p+min(a,(n%(a+b)))print(ans)C問題
問題
1WA
考えたこと
普通に計算しました。1WA出た理由は、for文のstopを1001ではなくて1000としたからです。このせいで、どちらかが答えが1000になるケースに対応できませんでした。みんなもforのstopには気を付けよう。
<追記>丸めると1009*0.10も100になるので、1010にしないといけない
importmatha,b=map(int,input().split())ans=[]foriinrange(1010):#ここを1000にしてた
price_8=math.floor(i*0.08)price_10=math.floor(i*0.1)ifprice_8==aandprice_10==b:ans.append(i)iflen(ans)!=0:print(min(ans))else:print(-1)まとめ
簡単なABCくらいなら深夜にでも解けることが分かった。おやすみなさい
↧
Spring Bootのプロジェクト構成で最初に知っておきたかったことをまとめた(maven)
フレームワークの勉強のために、Spring Bootを使ってみました。
Eclipseでプロジェクト作ったけど、構成とか後々自分で作るファイルをどこに置けばいいのかなど全然分からなくて困ったので、自分なりにまとめました。
前提:プロジェクト作成
プロジェクトの作成方法はたくさんインターネットに転がっているけど、前提がずれてしまうのはよくないので書きます。
- 新規プロジェクトを作成で「Spring スタータープロジェクト」を選択
次へ。
- 今回は、それぞれの項目を画像のように設定しました。

次へ。
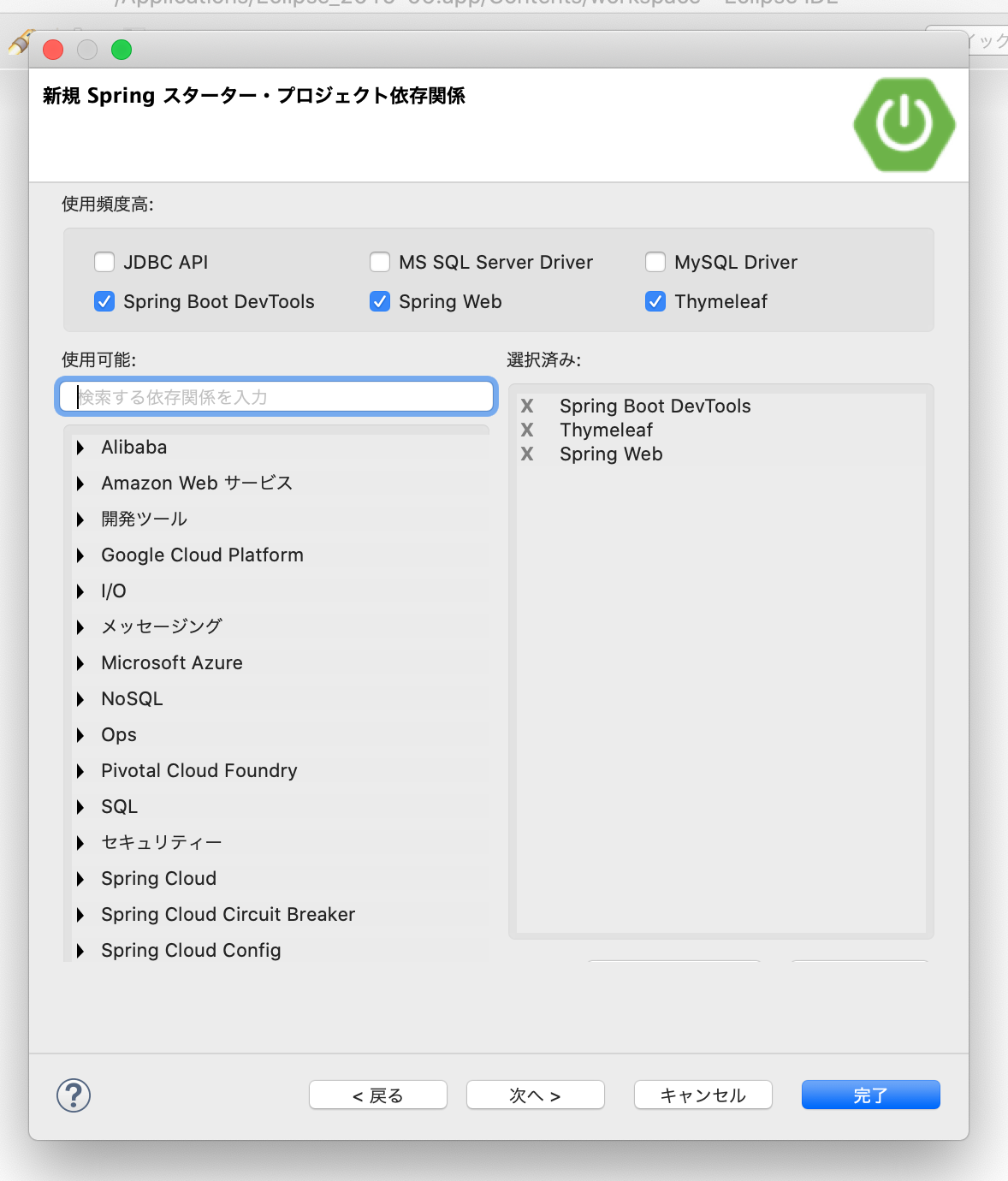
- 依存関係は、「Spring Boot DevTools」「Thymeleaf」「Spring Web」を選択しました。画面上部の「使用頻度高:」欄は無視してOKです。
次へ。
- こんな画面が出ますが、何もいじらずに。
完了!
構成はどうなっているの?
パッケージ・エクスプローラーを見ると、こんな感じになっています。
今回は、赤枠の中を見ていきます。(テストコードは書いていないので。。。)

src/main/java
名前からも分かりますが、ここにはjavaクラスが入ります。
MVCモデルでいう、Modelの操作とControllerの役割をもつクラスたちを置きます。
この中は、以下のような構成になっています。
src/main/java
├ com.myapp
├ MyAppSpringBootApplication.java
└ ServletInitializer.java
com.myapp
この中にクラスを作っていきます。
そのままクラスを作っても動きますが、きちんと設計をしてパッケージングすべし。(自戒)
たとえば、会員登録アプリなら、だいたい以下のようにするといいのでは思います。
com.myapp
├ controller //画面遷移や画面からの入力処理、セッション管理などを行う
│ └ UserDataController.java //会員情報のCRUD操作画面に対応したコントローラ
├ domain //そのアプリで使われるデータ(Beanクラスの集まり)
│ └ UserData.java //ユーザ情報のBeanクラス
├ repository //実際にDB接続してデータ操作をする(DAOクラスもおかれる)
│ └ UserDataRepository.java //ユーザ情報のCRUD操作をするクラス
└ service //ユースケースに表されるような業務をする
└ UserDataService.java //controllerで使うためのインターフェース的な役割
Springでは、慣例的に「xxxController」とか「xxxService」とか、命名規則があるようなので、それに従っておいた方が業務とかググる時に対応しやすいんじゃないかな、と思います。
MyAppSpringBootApplication.java
プロジェクトを起動するために必要なクラスです。大事です。
基本的に触りません。
プロジェクト起動時にしたい処理がある時、方法の一つとしてここで実装することもあるそうです。
プロジェクト作成時の「グループ」と「パッケージ」のcom.【この部分】が、
クラス名の【この部分】SpringBootApplication.javaに割り当てられるようです。
しかも1文字目を大文字にしてくれていますね。ありがたい。
ServletInitializer.java
TomcatなどのWebコンテナにデプロイするために必要なクラスです。大事です。
プロジェクト作成時に、パッケージングでWarを選択すると作られます。
こちらも基本的に触りません。
src/main/resources
ここは、MVCでいうViewに関するリソースを置きます。
この中は、以下のような構成になっています。
src/main/resources
├ static
├ templates
└ application.properties
static
この中には、cssやjavascriptのリソースが入ります。
だいたい以下のようになると思います。
static
├ css
└ js
templates
この中にhtmlファイルが入ります。
ちなみに、Controllerクラスの戻り値でtemplates直下のリソース名を指定すると、それが画面に表示されます。
画面のヘッダーやフッターを部品化して、各ページで使う時は、だいたい以下のようにするといいのでは思います。
templates
├ xxxx.html
├ yyyy.html
├ zzzz.html
└ parts
└ parts.html
application.properties
このプロジェクトで使う設定をするファイルです。
実際に開発する中で知っていったのですが、とにかくいろんな設定ができるっぽいです。
- ポート番号を明示的に指定
- DB接続設定
- バリデーションメッセージも!!(正直ここよりも、アノテーションを使って設定した方がいいと思いますが…)
など、、、
pom.xml
このxmlファイルは、プロジェクト作成時に設定した「依存関係」の設定が書かれています。
プロジェクト作成時に選択し忘れたり、追加で利用したい機能があれば、ここに書き足していきます。
おわり
初めて投稿しましたが、想像通り体力を使います。。。
アウトプット月間。これから頑張ります
↧
関数式と関数宣言の違い
はじめに
関数を定義する際、
JavaScriptでは、関数宣言または関数式を使用します。
今回は、この2つの違いについて、
説明していきます。
関数式、関数宣言
まずは、2つの記述方法について、
説明します。
関数宣言...
記述例↓↓
functioncolor(){document.write('white');}color(); //whiteと表示関数宣言は、「function 関数名」で関数を定義して、
「関数名()」で関数を呼び出す方法です。
関数式について..
記述例↓↓
letintroduce=function(){document.write("white");}introduce();//whiteと表示関数式は、
関数を間接的に使うやり方です。
変数に関数を値として代入し、後からその変数を呼び出す方法です。
本題の、違いについて...
上記2つの大きな違いは、
2点あります。
1.「無名関数」であるか? ないか?
2.「巻き上げ」 されるか? されないか?
になります。
無名関数とは、
言葉の通り、関数がないことです。
関数宣言、関数式の、
1列目の、
functionの後の記述方法を見て頂くと分かりますが...↓↓
//関数宣言functioncolor()//関数式letintroduce=function()上記の通り、
functionの後に関数名が、記述されていない、
関数式が「無名関数」になります。
※関数式は、関数名ありで定義することも出来ます。
ただし、基本的には「無名関数」で定義しましょう。
巻き上げとは...
関数の実行文を先に記述しても、
問題なく実行されることです。
有無について...
関数宣言→巻き上げ有り
関数式→巻き上げ無し
になります。
記述例↓↓
color(); functioncolor(){document.write('white');}//whiteと記述関数宣言では、
巻き上げが有りなので、
上記の記述方法でも、実行されます。
結論
関数宣言と、関数式は
どちらを使った方が良いのかよく分からず、調べました。
結果...
ほとんどの場合、どちらでもよい。
という、意見がほとんどでした。
両方の本質を知り、
理解した上で、
関数を定義していきましょう。
私の考え
私的にですが、
関数式を使用していきたいと思っています。
理由は、
関数名を考える手間をなくすことが出来るからです。
本日はありがとうございました。
↧
↧
Pythonで高校数学の集合の問題を解いてみる
この記事について
この記事は「高校数学の集合の簡単な問題をPythonで解いてみよう!」という記事です。
やっていくことはかなり初歩的で、わざわざPythonでやるよりも直接やるほうが楽ですが、Pythonで色んなことができる楽しさを残しておきたい(主に自分に向けて)のでやっていこうと思います。
記号についての復習
以下、A,Bは集合とする。
・A∪B:和集合と呼ばれるもの。A,Bの少なくとも一方に属する要素全体の集合。
・A∩B:共通部分と呼ばれるもの。A,Bのどちらにも属する要素全体の集合。
ex) A={1,2,3,4,5} B={2,4,6}のとき、A∪B={1,2,3,4,5,6} , A∩B={2,4} となる。
集合の範囲では、あらかじめ一つの集合を定めてからその部分集合について考えることが多いです。その時、あらかじめ定めた集合のことを全体集合と呼び、Uで置くことが多いです。
_
・A:補集合と呼ばれるもの。全体集合Uの部分集合Aに対して、Uの要素でAに属さないものの全体の集合。この記事では都合上A_cなどと書かせていただきます。すいません。
ex) U={x|xは10より小さい自然数} A={2,4,6,8}のとき、A_c={1,3,5,7,9}
Pythonでは
Pythonでは以下のように書きます。
set.py
>>>A|B#A,Bに含まれるすべての要素を持った新しい集合型変数を作成。すなわち、AとBの和集合。
>>>A&B#A,Bに共通に含まれる要素を持った新しい集合型変数を作成。すなわち、AとBの共通部分。
>>>A-B#Aには含まれるがBには含まれない要素を持った新しい集合型変数を作成。すなわち、Aを全体集合としたときの、Bの補集合。
問題を解いてみよう
早速、問題を解いていきましょう。なお以下では、A∩BをcapAB , A∪BをcupABと書くことがあります。ご了承ください。
1 . 次の集合A , BについてA∩B , A∪Bを求めよ。
(1)A = {1,2,3,4,5} , B = {2,3,5,7}
1-1.py
>>>A={1,2,3,4,5}>>>B={2,3,5,7}#まずは集合AとBを定義しましょう。
>>>capAB=A&B#上記より、共通部分を求めたい場合は&を用いる。
>>>capAB{2,3,5}>>>cupAB=A|B#上記より、和集合を求めたい場合は|を用いる。
>>>cupAB{1,2,3,4,5,7}よって答えは、A∩B={2,3,5} , A∪B={1, 2, 3, 4, 5, 7}となります!
(2)A = {x|xは24の正の約数} , B = {x|xは32の正の約数}
1-2.py
>>>A={1,2,3,4,6,8,12,24}>>>B={1,2,4,8,16,32}>>>capAB=A&B>>>capAB{8,1,2,4}>>>cupAB=A|B>>>cupAB{32,1,2,3,4,6,8,12,16,24}よって答えは、A∩B={1,2,4,8} , A∪B={1,2,3,4,6,8,12,16,24,32}となります!
2 . A={1,2,3,4,5,6},B={2,4,6,8,10},C={1,2,4,8,16}のとき、A∩B∩C,A∪B∪Cを求めよ。
2.py
>>>A={1,2,3,4,5,6}>>>B={2,4,6,8,10}>>>C={1,2,4,8,16}>>>X=A&B>>>capXC=X&C>>>capXC{2,4}>>>Y=A|B>>>cupYC=Y|C>>>cupYC{1,2,3,4,5,6,8,10,16}よって答えは、A∩B∩C={2,4} , A∪B∪C={1,2,3,4,5,6,8,10,16}となります!
3 . U={x|xは10より小さい自然数},A={2,4,6},B={1,3,4,7}について、次の集合を求めよ。
(1)A_c
3-1.py
>>>U={1,2,3,4,5,6,7,8,9,10},>>>A={2,4,6}>>>A_c=U-A#上記より、補集合を求める場合は-を用いる。
>>>A_c{1,3,5,7,8,9,10}よって答えは、A_c={1,3,5,7,8,9,10}となります!
(2)A∩(B_c)
3-2.py
>>>U={1,2,3,4,5,6,7,8,9,10}>>>A={2,4,6}>>>B={1,3,4,7}>>>B_c=U-B>>>capAB_c=A&B_c>>>capAB_c{2,6}よって答えは、A∩B_c={2,6}となります!
(3)(A_c)∪(B_c)
3-3.py
>>>U={1,2,3,4,5,6,7,8,9,10}>>>A={2,4,6}>>>B={1,3,4,7}>>>A_c=U-A>>>B_c=U-B>>>cupA_cB_c=A_c|B_c>>>cupA_cB_c{1,2,3,5,6,7,8,9,10}よって答えは、(A_c)∪(B_c)={1,2,3,5,6,7,8,9,10}となります!
(4)(A∩B)_c
3-4.py
>>>U={1,2,3,4,5,6,7,8,9,10}>>>A={2,4,6}>>>B={1,3,4,7}>>>capAB=A&B>>>c_capAB=U-capAB>>>c_capAB{1,2,3,5,6,7,8,9,10}よって答えは、(A∩B)_c={1,2,3,5,6,7,8,9,10}となります!
最後に
以上で終わりとなります。
問1-2などで約数が集合の要素となっている場面がありました。そこで、約数を求める過程もpython内でできると思うので、手が空いたら更新したいと思います。
何か誤り等ございましたら、ご報告ください。ありがとうございました。
↧
C#でクラスライブラリを開発する時に必ずやった方が便利な設定
はじめに
C#でクラスライブラリを開発する時に、必ずやった方が便利な設定の紹介です。
前提として、その開発したクラスライブラリのDLLファイルが、別のソリューション(.sln)から参照される場合を想定しています。
(同じソリューション内で[プロジェクト]の参照しかしない場合は、本稿の設定をしなくても問題ありません)
デフォルト設定のままで不便なこと
開発したクラスライブラリを、デフォルト設定のままで別のソリューションから参照させた場合、以下の2つの不便なことが起きます。
ここで言う「デフォルト設定」とは、Release ビルドしたDLLファイルを参照させた場合を意味します。
インテリセンスでコメントが表示されない
開発したクラスライブラリが、以下のようにプロパティやメソッドのコメントを記載しているとします。
/// <summary>/// 人を表すクラス/// </summary>publicclassPerson{/// <summary>/// 名前/// </summary>publicstringName{get;set;}/// <summary>/// 指定されたメッセージで挨拶する/// </summary>/// <param name="message">メッセージ</param>publicvoidGreet(stringmessage){Console.WriteLine(message);}}しかし、そのDLLファイルを参照させた別のプロジェクトから利用する際に、メソッドのコメントがインテリセンスで表示されません。

デバッグ実行時にステップインができない
デバッグ実行時に、参照しているDLLのクラスのメソッドにステップインしたいと思っても、ステップインできません。
お勧めする便利な設定
以下の設定を行うことで、両方の問題が解消できます。
インテリセンスでコメントが表示されるようにする
-doc (C# コンパイラ オプション) を付けることで、XML ファイル内にドキュメント コメントを含めることができます。
具体的には、以下の手順でプロジェクト設定を変更すると、ビルド時にDLLファイルと同じフォルダにXMLファイルが作成されます。
- プロジェクトの [プロパティ] ページを開きます。
- [ビルド] タブをクリックします。
- [XML ドキュメント ファイル] プロパティにチェックを付けます。
-doc の詳細は以下を参照ください。
-doc (C# コンパイラ オプション) | Microsoft Docs
上記で作成したXMLファイルを、参照するDLLファイルと同じフォルダに格納しておけば、DLLファイルの読み込み時に、XMLも一緒に読み込んでくれます。その結果、下図のように、インテリセンスでコメントも表示されるようになります。

デバッグ実行時にステップインできるようにする
デバッグ実行するためには、ビルド時にDLLと一緒に生成される pdbファイルが必要になります。また、Releaseビルドのファイルではデバッグ実行できないため、Debugビルドのファイルに差し替える必要があります。
従って、DebugビルドしたDLLとpdbファイルを同じフォルダに格納し、そのDLLファイルを参照させることで、そのDLLのメソッドをステップ実行できます。
詳細は以下を参照ください。
Visual Studio デバッガーでシンボル (.pdb) ファイルとソース ファイルの指定 (C#、C++、Visual Basic、 F#) | Microsoft Docs
下図は、DLLファイルを参照したプロジェクトから、DLL内のクラスのメソッドにステップインした時の画面です。ソースコードのコメントや行番号も確認できます。

なお、テスト実施やリリースの際には、Release ビルドのDLLを利用する必要があるため、別途 ReleaseビルドのDLLを別フォルダに格納しておくことをお勧めします。インストーラを作成するスクリプトなどは、ReleaseビルドのDLLを利用するように設定しておくと良いと思います。
まとめ
DebugビルドしたDLLとXMLとpdbのファイルを同じフォルダに格納した上で、参照させると便利です。
私は上記手法を用いて こちらのツールを作っています。
Twitterでも開発に役立つ情報を発信しています → @kojimadev
↧
【初心者向け】今度こそわかるDI〜DIの基礎とSpringにおけるDI〜
はじめに
DIとはDependency Injectionの略であり、日本語では「依存性の注入」と訳されることが多いです。
新卒だったころにSpringに触れた私は、初めてこの概念を聞いた時に頭に浮かんだのは、はてなマークでした。DIの概念やDIコンテナ、Springにおけるアノテーションとの結びつきがピンとこなかったのです。
今回は初心者だったころの自分にあてて、DIの概念およびSpringにおけるDIについて自分なりに整理しつつ、簡単にまとめていきたいと思います。
依存性(Dependency)とは
依存(性)とは何かということはソースコードで示したほうがわかりやすいと思います。
Main.java
publicclassMain{publicinthoge(){varsub=newSub();returnsub.calculate();}}Mainクラスのhogeメソッド内で、Subクラスのインスタンスを生成し、利用しています。
このようなMainクラスがあったとき、「MainクラスはSubクラスに依存している」と表現します。
依存に関しては比較的わかりやすいと思います。
注入(Injection)とは
先程の例では、Subクラスのインスタンスを内部で生成していましたが、インスタンスを外部で生成し、それを用いるクラスに渡してあげることを注入と呼びます。
ここでは、コンストラクタを用いた例(コンストラクタインジェクション)を示します。
Main.java
publicclassMain{privateSubsub;publicinthoge(){returnsub.calculate();}// コンストラクタインジェクションpublicMain(Subsub){this.sub=sub;}}先程はhogeメソッド内でSubクラスのインスタンスを生成していましたが、今回の例では、インスタンスをコンストラクタから受け取るようになっています。
このようにすることで、Mainクラスを実際に用いる際は、
varsub=newSub();varmain=newMain(sub);といった形で、SubクラスのインスタンスをMainクラスの外から渡す形になります。
これによるメリットは後述します。
DIコンテナとは
コンテナと聞くと現代ではDockerを連想するかもしれませんが、DIコンテナにおけるコンテナはDockerなどの文脈で用いられるコンテナと異なります。
誤解を恐れず一言で書くとすると、DIコンテナは「注入するインスタンスを管理してくれる入れ物」の役割をしてくれます。
先程のようにDIコンテナを用いずに、Mainクラスを用いようとすると、用いるたびにSubクラスのインスタンスが必要になります。
DIコンテナを用いると、このインスタンスを管理してくれるので、いちいちインスタンスを生成する必要がなくなります。
SpringにおけるDIコンテナ
Springではアノテーションでクラスを指定することで、そのクラスのインスタンスをDIコンテナで管理する対象として指定することができます。
具体的には以下のようなアノテーションです。
@Controller@Service@Repository@Bean
ちなみに、DIコンテナで管理されているインスタンスはApplicationContextクラスのgetBeanメソッドを用いることで、取得することができます。
また、SpringではDIコンテナがインスタンスをいつまで管理するかという、スコープを設定することができます。
設定できるスコープは下記のとおりで、設定する際はScopeアノテーションを用います。
- singleton
- prototype
- request
- session
- global session
Springのデフォルトはsingletonになっていますが、設定を変更することにより、例えばsession単位で、コンテナに管理されているインスタンスを破棄し、再設定するといったことが可能になります。
初心者がやりがちな注意点としては、singletonにもかかわらず、クラスに変化しうるフィールドを持たせてしまうことです。以下に例を示します。
hogeService
@ServicepublicclasshogeService{privateStringresult;publicintfuga(Stringsuffix){result="test"+suffix;returnresult;}}hogeServiceにはServiceアノテーションが付与されており、特にスコープを設定していないので、スコープがsingletonになります。
そのため、resultフィールドを別のセッションで変更してしまう危険性があり、スレッドセーフでなくなってしまいます。
下記のようにクラスフィールドではなく、変数にしてあげることで、スレッドセーフな実装になります。
hogeService
@ServicepublicclasshogeService{publicintfuga(Stringsuffix){Stringresult="test"+suffix;returnresult;}}SpringにおけるDI
Springでは、Autowiredアノテーションを用いることで、DIすることができます。
インジェクションの方法には先程のコンストラクタインジェクションも含め、下記の3つがあります。
- フィールドインジェクション
- セッターインジェクション
- コンストラクタインジェクション
それぞれ具体的には、このようになります。
Main.java
publicclassMain{// フィールドインジェクション@AutowiredprivateSubsub;publicinthoge(){returnsub.calculate();}}Main.java
publicclassMain{privateSubsub;publicinthoge(){returnsub.calculate();}// セッターインジェクション@AutowiredpublicsetSub(Subsub){this.sub=sub;}}Main.java
publicclassMain{privateSubsub;publicinthoge(){returnsub.calculate();}// コンストラクタインジェクション@AutowiredpublicMain(Subsub){this.sub=sub;}}Autowiredアノテーションを付与することで、フィールド、メソッドおよびコンストラクタの引数にDIコンテナからインスタンスを注入してくれます。
ちなみに自分がインジェクションする際は、こちらの記事にあるように、ライブラリのLombokのRequiredArgsConstructorアノテーションを用いて書いています。
DIのメリット
よく言われるメリットとして、単体テストが書きやすくなることが挙げられますが、
これはそのとおりだと私も思います。
冒頭の例をもう一度示します。
Main.java
publicclassMain{publicinthoge(){varsub=newSub();returnsub.calculate();}}仮にこのSubクラスのcalculateメソッドが、DBにアクセスする必要があったとすると、Mainクラスの単体テストは非常に難しくなります。
しかし、DIによって注入するインスタンスをモックにすることで、テストすることができます。
ちなみに私はモックを用いる際はMockitoを用いています。
まとめ
最後に、改めてDIおよびDIコンテナについて一言でまとめると下記のようになります。
DI:あるクラスに対して依存しているクラスのインスタンスを外部から渡してあげること
DIコンテナ:注入するインスタンスを管理してくれる入れ物
これらを用いることで、テストが書きやすくなったり、スコープの管理がしやすくなったりというメリットがあります。
内容は以上です。本記事が少しでもお役に立てば幸いです。
最後までお読み頂き、ありがとうございました。
参考文献
公式ドキュメント
Core Technologies
↧









