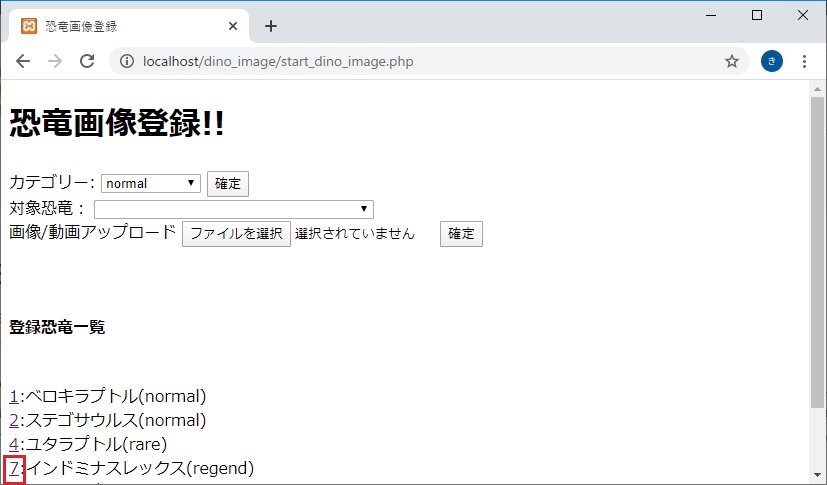
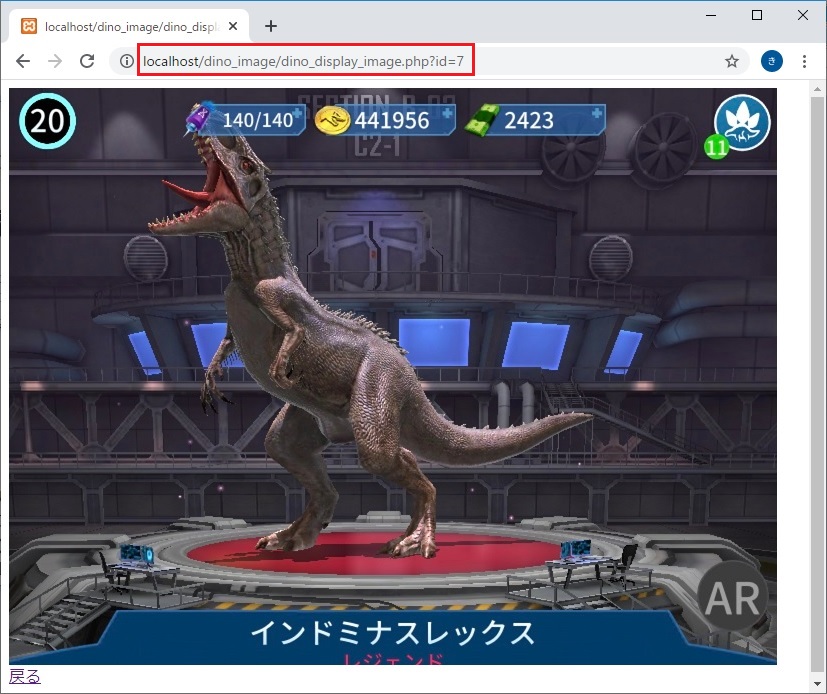
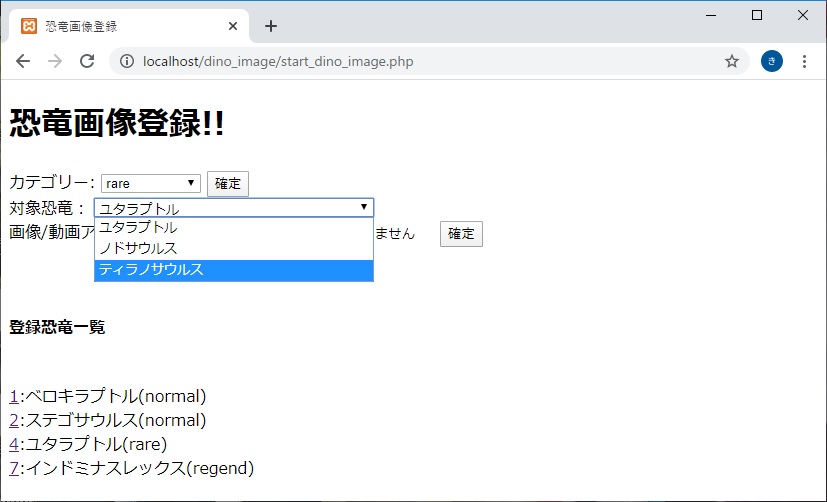
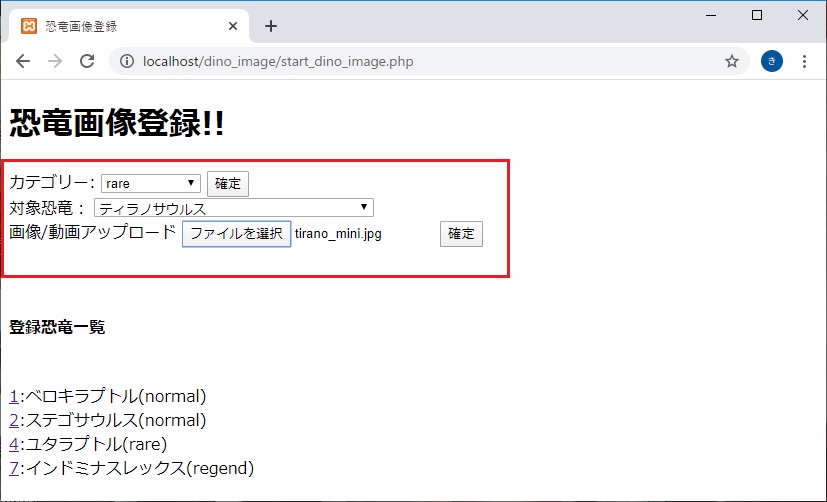
きっかけ
COTOHAに関して、自分の前の記事とかでちょっとは触っていた。そんな中、あるQiitaの広告に気づく。
今、言語処理100本ノック 2015を進めているところではあるが、これは参加しないわけにはいかない。
ネタ探し
おそらくここが一番難しい所。明確に何か目的がある時にはよいけども、いざ何かネタを探そうとするとうまい事思いつかないのが世の常。お笑い芸人の皆さんは、ネタ帳を持ち歩き、ネタになりそうなものを探して気づいたら書き留めているという話。しかし締め切りは3月15日。明日。
あがく(その1)
既にこのキャンペーンに参加している人はたくさんいる。COTOHA開発者ブログを見ると色々なアイデアがそろっていて、見ているだけで面白い。そして同時にヒントになるものが無いか探しまくる。そして気づく。他の人のアイデアを見てもそれを超える事を思いつくのは難しい事に。ただ、雰囲気は感じる事が出来た。このあがきは無駄ではなかった。
ここで気づいた事。ここはシンプル行くべき。時間も無い。
あがく(その2)
前述ステップでもう一つ気づいた事。COTOHA APIには各種機能が準備されている。それぞれの具体的な使用例も挙げてくれている。一度ちゃんと一通り目を通しておくべき。ここで前準備期間がもう少しあれば何か思いついたかもしれない。もっと早い段階で読んでおくべきだった。
API一覧
あがく(その3)
この時点では実はちょっと諦め気分。でも諦めきれない。すでに時遅しかもしれないが、色々な文章を色々なサービスに投入してその結果を見てみると何か面白いものが出てくるかもしれない。
自然言語処理を簡単に扱えると噂のCOTOHA APIをPythonで使ってみた
のAPIライブラリ(?)を利用させて頂く。
使う文章は 自分が書いた前の記事「courseraのMachineLearningを修了。それに関して思いを馳せてみた。」。ポエムとして書いた文章なので、解析対象としては比較的適切と判断。とりあえず、キーワード抽出を使って何かつかめないか見てみる。
少し改造させて頂く(投稿文章はsample.txtに保存済み)
# ・・前略・・
# キーワード抽出API
defkeyword(self,document,max_keyword_num=5):#キーワードの上限個数に対応
# キーワード抽出API URL指定
url=self.developer_api_base_url+"v1/keyword"# ヘッダ指定
headers={"Authorization":"Bearer "+self.access_token,"Content-Type":"application/json;charset=UTF-8",}# リクエストボディ指定
data={"document":document,"max_keyword_num":max_keyword_num#この部分を追加させてもらう
}# ・・中略・・
#メイン部分
try:test_data=open("sample.txt","r")test_lines=test_data.readlines()sentence=test_lines# キーワード抽出API
result=cotoha_api.keyword(sentence,max_keyword_num=10)# 出力結果を見やすく整形
result_formated=json.dumps(result,indent=4,separators=(',',': '))print(codecs.decode(result_formated,'unicode-escape'))finally:test_data.close()実行結果
コンソール出力
{"result": [{"form": "色々",
"score": 81.724014
},
{"form": "機械学習",
"score": 58.11082
},
{"form": "知識",
"score": 54.63603
},
{"form": "自分",
"score": 50.586876
},
{"form": "万能",
"score": 39.102345
},
{"form": "簡単",
"score": 32.145184
},
{"form": "活用",
"score": 27.079329
},
{"form": "世の中",
"score": 26.16732
},
{"form": "部分",
"score": 25.904205
},
{"form": "勉強",
"score": 24.463238
}],
"status": 0,
"message": ""}
突出して「色々」がポイント高いw。数えてみたら10回使ってる。恐らく一般的な文章と比べて出現頻度が高い単語がキーワードとして選ばれている。言い換えればここに自分が思ってない単語が出てきていたらそれは口癖みたいなものだろう。ちなみに今回の文章も既に3回使っている。
希望としては「知識レイヤ」とかの単語が出てきてほしかった。
でもこれはこれで、自分が書いた文章の特徴が出てきて面白い。そして変に同じフレーズを繰り返していないかのチェックに使えそう。
という事で、投稿テーマをQiitaに投稿する(に限らないが)文章のチェックにCOTOHAを活用する事に決める。
投稿文章チェックしてみる
「不用意なフレーズ繰り返しチェック」「文章口調チェック」「感情チェック」のチェックを行いたい。
不用意なフレーズ繰り返しチェック
これは前述のキーワード抽出そのまま。トップ10の中に自分が表現したかった事と違っている単語が入っていたら見直し対象にする。
文章口調チェック
校正でチェックする事の一つに口調のチェックがある。「です・ます調」「だ・である調」を両方使ってはいけないというルール。両方の回数をチェックする事で見直す事が出来るようにする。
形態素解析
まずは、形態素解析をしてみる。analyze_all.json に出力は保存。
構文解析にはparseを使用
# 解析対象文
try:test_data=open("sample.txt","r")test_lines=test_data.readlines()# sentence = ' '.join(test_lines)
sentence=test_lines# 構文解析API実行(全角スペースで全文章をつなげる)
result=cotoha_api.parse(' '.join(sentence))# 出力結果を見やすく整形
result_formated=json.dumps(result,indent=4,separators=(',',': '))print(codecs.decode(result_formated,'unicode-escape'))finally:test_data.close()実行結果
階層及び句点近辺
{"result":[{"chunk_info":{"・・中略・・":""},"tokens":[{"・・中略・・":""}]},{"chunk_info":{"id":347,"head":351,"dep":"P","chunk_head":0,"chunk_func":3,"links":[]},"tokens":[{"id":927,"form":"には","kana":"ニハ","lemma":"には","pos":"連用助詞","features":[],"attributes":{}},{"id":928,"form":"い","kana":"イ","lemma":"いる","pos":"動詞語幹","features":["A"],"attributes":{}},{"id":929,"form":"る","kana":"ル","lemma":"る","pos":"動詞接尾辞","features":["終止"],"attributes":{}},{"id":930,"form":"。","kana":"","lemma":"。","pos":"句点","features":[],"attributes":{}}]},
文末品詞チェック
result[?].tokens[?] を調べて、pos(品詞)が"句点"のものを見つけ、その手前の文言を調べればよさそう。※posは「Part of speech」の事らしい。
importjsonjson_file=open("analyze_all.json","r")try:wk_lines=json_file.readlines()# sentence = ' '.join(test_lines)
joson_str=''.join(wk_lines)json_body=json.loads(joson_str)result=json_body['result']forchunkinresult:wkstr=''tokens=chunk['tokens']foridx,tokeninenumerate(tokens):wkstr+=token['form']iftoken['pos']=='句点'andidx>=1:print('{0:s} 終了品詞:{1:s}'.format(wkstr,tokens[idx-1]['pos']))finally:json_file.close()実行結果
階層及び句点近辺
考えてみた。 終了品詞:動詞接尾辞
してみたい。 終了品詞:動詞接尾辞
ない。 終了品詞:形容詞接尾辞
良い。 終了品詞:形容詞接尾辞
受講開始。 終了品詞:名詞
チャレンジしてみたくもなった。 終了品詞:動詞接尾辞
終わった。 終了品詞:動詞接尾辞
修了。 終了品詞:名詞
思う)。 終了品詞:括弧
思う。 終了品詞:動詞接尾辞
支払った。 終了品詞:動詞接尾辞
感覚)。 終了品詞:括弧
簡単ではない。 終了品詞:形容詞接尾辞
実感。 終了品詞:名詞
述べられてる。 終了品詞:動詞接尾辞
痛感。 終了品詞:名詞
事も。 終了品詞:連用助詞
つながる。 終了品詞:動詞接尾辞
知った。 終了品詞:動詞接尾辞
解る。 終了品詞:動詞接尾辞
様子。 終了品詞:名詞
思う。 終了品詞:動詞接尾辞
もの。 終了品詞:接続接尾辞
楽しそう。 終了品詞:形容詞接尾辞
よる。 終了品詞:動詞接尾辞
見つかる。 終了品詞:動詞接尾辞
深めたい。 終了品詞:動詞接尾辞
クソアプリ。 終了品詞:名詞
思われる。 終了品詞:動詞接尾辞
考察していきたい。 終了品詞:動詞接尾辞
感じる。 終了品詞:動詞接尾辞
諦めた。 終了品詞:動詞接尾辞
思う。 終了品詞:動詞接尾辞
事。 終了品詞:名詞
使われる。 終了品詞:動詞接尾辞
感じ。 終了品詞:名詞
思われ。 終了品詞:動詞接尾辞
無かった。 終了品詞:形容詞接尾辞
世の中にはいる。 終了品詞:動詞接尾辞
復習してみました。 終了品詞:動詞接尾辞
思う。 終了品詞:動詞接尾辞
しそう。 終了品詞:動詞接尾辞
思う。 終了品詞:動詞接尾辞
呼べたりするのかな? 終了品詞:終助詞
持ってるらしい。 終了品詞:形容詞接尾辞
ライブラリ? 終了品詞:名詞
事らしい。 終了品詞:形容詞接尾辞
書かれてた。 終了品詞:動詞接尾辞
思う。 終了品詞:動詞接尾辞
思う。 終了品詞:動詞接尾辞
あったし。 終了品詞:接続接尾辞
スムースになる。 終了品詞:動詞接尾辞
ありそう。 終了品詞:動詞接尾辞
痛感。 終了品詞:名詞
思う。 終了品詞:動詞接尾辞
レベル。 終了品詞:名詞
感じた。 終了品詞:動詞接尾辞
必要。 終了品詞:名詞
必要。 終了品詞:名詞
感じる。 終了品詞:動詞接尾辞
感じ。 終了品詞:名詞
あるかな? 終了品詞:終助詞
思う。 終了品詞:動詞接尾辞
あった。 終了品詞:動詞接尾辞
あるか? 終了品詞:終助詞
はず。 終了品詞:名詞
思う。 終了品詞:動詞接尾辞
感謝です。 終了品詞:判定詞
はず。 終了品詞:名詞
想定される。 終了品詞:動詞接尾辞
使っているらしい。 終了品詞:形容詞接尾辞
使われてるらしい。 終了品詞:形容詞接尾辞
思う。 終了品詞:動詞接尾辞
思う。 終了品詞:動詞接尾辞
思う。 終了品詞:動詞接尾辞
思う。 終了品詞:動詞接尾辞
あるかもしれない)。 終了品詞:括弧
予定。 終了品詞:名詞
なってしまった。 終了品詞:動詞接尾辞
ありがとうございました。 終了品詞:独立詞
「復習してみました」がちょっと違うな、と思ってみてみたら、引用させてもらった他の投稿のタイトルだった。結構「だ・である調」は守れていたらしい。しかし、「思う」で終わってる文章が多い。まぁ「思いを馳せてみる」ポエムなのである意味妥当w。
感情チェック
各文章の感情をチェックして、意図せぬ感情起伏になってないかチェック。
sentimentのAPIは 自然言語処理を簡単に扱えると噂のCOTOHA APIをPythonで使ってみたが投稿されたときには無かったのか、ソース中になかったので、他の関数のをコピーして追加。
# 文タイプ判定API
defsentiment(self,sentence):# 文タイプ判定API URL指定
url=self.developer_api_base_url+"v1/sentiment"# ヘッダ指定
headers={"Authorization":"Bearer "+self.access_token,"Content-Type":"application/json;charset=UTF-8",}# リクエストボディ指定
data={"sentence":sentence}# リクエストボディ指定をJSONにエンコード
data=json.dumps(data).encode()# リクエスト生成
req=urllib.request.Request(url,data,headers)# リクエストを送信し、レスポンスを受信
try:res=urllib.request.urlopen(req)# リクエストでエラーが発生した場合の処理
excepturllib.request.HTTPErrorase:# ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト
ife.code==401:print("get access token")self.access_token=self.getAccessToken(self.client_id,self.client_secret)headers["Authorization"]="Bearer "+self.access_tokenreq=urllib.request.Request(url,data,headers)res=urllib.request.urlopen(req)# 401以外のエラーなら原因を表示
else:print("<Error> "+e.reason)# レスポンスボディ取得
res_body=res.read()# レスポンスボディをJSONからデコード
res_body=json.loads(res_body)# レスポンスボディから解析結果を取得
returnres_bodyこんな感じで出力してsentiment.jsonにファイル保存。
try:test_data=open("sample.txt","r")test_lines=test_data.readlines()# sentence = ' '.join(test_lines)
sentence=test_linesjoined_sentence=''.join(test_lines)sentence_list=joined_sentence.split('。')print('[')forsentenceinsentence_list:result=cotoha_api.sentiment(sentence)result_formated=json.dumps(result,indent=4,separators=(',',': '))print(codecs.decode(result_formated,'unicode-escape'))print(',')print(']')finally:test_data.close()1リクエストの結果例
{"result":{"sentiment":"Positive","score":0.5401555923096191,"emotional_phrase":[{"form":"流行り","emotion":"P"}]},"status":0,"message":"OK"}実行結果
jsonを処理して出力した結果
Neutral 0.268624 []
Positive 0.540156 [{'form': '流行り', 'emotion': 'P'}]
Neutral 0.303050 []
Positive 0.271682 [{'form': '良い', 'emotion': 'P'}]
Positive 0.071115 [{'form': '良い', 'emotion': 'P'}, {'form': 'まずは無料', 'emotion': 'P'}, {'form': 'カッコよくて欲しい', 'emotion': 'P'}]
Neutral 0.291507 []
Positive 0.363525 [{'form': '強く沸き上がり', 'emotion': 'P'}]
Neutral 0.274798 []
Neutral 0.264217 []
Positive 0.585754 [{'form': '早い', 'emotion': 'P'}]
Positive 0.256760 [{'form': '良い', 'emotion': 'P'}]
Neutral 0.231494 []
Negative 0.774002 [{'form': 'いけない', 'emotion': 'N'}, {'form': '簡単ではない', 'emotion': 'PN'}]
Positive 0.599232 [{'form': '実感', 'emotion': 'P'}]
Neutral 0.269050 []
Positive 0.092880 [{'form': 'よい', 'emotion': 'P'}, {'form': '適切な', 'emotion': 'P'}, {'form': '正確さ', 'emotion': 'P'}, {'form': '痛感', 'emotion': 'P'}]
Negative 0.829964 [{'form': '長い時間がかかる', 'emotion': 'N'}, {'form': '失敗すると', 'emotion': 'N'}, {'form': '多大な', 'emotion': 'PN'}]
Neutral 0.296784 [{'form': 'ダイレクトな', 'emotion': 'PN'}]
Neutral 0.346448 []
Positive 0.247956 [{'form': '簡単', 'emotion': 'PN'}, {'form': '解る', 'emotion': 'P'}]
Neutral 0.383904 []
Neutral 0.247514 [{'form': '簡単ではない', 'emotion': 'PN'}]
Neutral 0.369362 []
Positive 0.389558 [{'form': 'やっぱり楽しそう', 'emotion': 'P'}]
Neutral 0.292794 []
Negative 0.769889 [{'form': '初心者向け', 'emotion': 'N'}]
Neutral 0.334311 []
Positive 0.589350 [{'form': '壮大な', 'emotion': 'P'}]
Neutral 0.341264 [{'form': '簡単な', 'emotion': 'PN'}]
Neutral 0.350338 []
Positive 0.347399 [{'form': '知識があった', 'emotion': 'P'}, {'form': '比較的スムース', 'emotion': 'P'}]
Negative 0.660826 [{'form': '諦めた', 'emotion': 'N'}, {'form': 'なんとかなると', 'emotion': 'PN'}]
Neutral 0.271371 []
Negative 0.691616 [{'form': '無理だったろう', 'emotion': 'N'}]
Neutral 0.286343 []
Positive 0.669637 [{'form': '良い', 'emotion': '喜ぶ'}, {'form': '理解', 'emotion': 'P'}, {'form': 'なお良い感じ', 'emotion': 'P'}]
Positive 0.600185 [{'form': '役に立つと', 'emotion': 'P'}]
Neutral 0.255581 [{'form': '忘れていなかった', 'emotion': 'PN'}]
Neutral 0.368193 []
Neutral 0.354854 []
Neutral 0.343578 []
Negative 0.871992 [{'form': 'ただとらわれすぎると', 'emotion': 'N'}]
Neutral 0.331474 []
Neutral 0.425332 []
Positive 0.333227 [{'form': '必要ある', 'emotion': 'P'}]
Neutral 0.265064 [{'form': 'なんとかなると', 'emotion': 'PN'}]
Positive 0.536926 [{'form': '間違いではない', 'emotion': 'P'}]
Positive 0.629587 [{'form': '対応可能と', 'emotion': 'P'}]
Neutral 0.342275 []
Positive 0.505652 [{'form': '理解', 'emotion': 'P'}, {'form': 'スムース', 'emotion': 'P'}]
Negative 0.669981 [{'form': '理解できず間違った', 'emotion': 'N'}]
Positive 0.468893 [{'form': 'よかった', 'emotion': '喜ぶ'}, {'form': '痛感', 'emotion': 'P'}]
Neutral 0.223020 []
Neutral 0.223959 [{'form': '普通', 'emotion': 'PN'}]
Neutral 0.196458 []
Neutral 0.224248 [{'form': '必要', 'emotion': 'PN'}]
Neutral 0.290354 [{'form': '必要', 'emotion': 'PN'}]
Positive 0.773919 [{'form': '絡', 'emotion': '怒る,嫌'}, {'form': '複雑', 'emotion': 'PN'}, {'form': '綺麗な', 'emotion': 'P'}]
Neutral 0.426518 [{'form': '良かった', 'emotion': 'P'}, {'form': '必須でなく', 'emotion': 'N'}]
Neutral 0.159759 [{'form': '相当な', 'emotion': 'PN'}]
Neutral 0.217347 [{'form': '数学的', 'emotion': 'PN'}]
Positive 0.230669 [{'form': '理解する', 'emotion': 'P'}]
Neutral 0.276439 []
Positive 0.639602 [{'form': '感謝です', 'emotion': 'P'}]
Neutral 0.296018 []
Neutral 0.360645 [{'form': '相当な', 'emotion': 'PN'}]
Neutral 0.477751 []
Neutral 0.377498 []
Neutral 0.328837 []
Neutral 0.241177 []
Positive 0.438030 [{'form': '進化', 'emotion': 'P'}]
Positive 0.460860 [{'form': '進化', 'emotion': 'P'}, {'form': '効率的な', 'emotion': 'P'}]
Neutral 0.400177 []
Neutral 0.275407 []
Neutral 0.278125 []
Neutral 0.336289 []
グラフにするとこんな感じ。
![image.png]()
ん?センチメントスコアはPositive/Negativeとは関係ない?Positiveを0、Negativeを-1にしてみる。
![image.png]()
少々Negativeもあるけど、基本的にPositive基調の様子。Positive過ぎもしない。問題無いかな。
感想
本当は下書き保存時のURL指定すると、文章を抽出して一連の処理を一括でやれるようにしたり、グラフ描画とかも一括でやりかった。けど、ちょっと対応に時間かかりそうなので今回は諦めた。
自然言語処理を使って、ささやかながらも何かできた、という感覚を持てた。よかった。
終わりに
自分と同じように、何かしたいと思った時に、その何かを思いつくのが大変という人は多いはず。
基本的には、ネタ探しの部分とか切り捨てる文章だけど、同じように悩んでいる人にとって少しでも参考になればと思いそのままにしてます。
参考にさせてもらったページ
自然言語処理を簡単に扱えると噂のCOTOHA APIをPythonで使ってみた
COTOHA開発者ブログ